这是一篇翻译,原文在这里:Macro View of Map Internals In Go
简介
有很多文章来介绍golang slice的内部实现,但是当涉及到map的时候,都有点说不清楚。在好奇之余,去查看了golang map的源代码,知道大家为什么都懵逼了,源代码链接:
https://golang.org/src/runtime/hashmap.go
至少对我来说,这代码太复杂了,既然如此,我尝试从宏观角度去理解map是怎么构建的,以及怎么扩展(grow)的,通过这样,可以解释为什么map是无序的、高效的。
创建和使用map
我们先来看一下,map是如何创建以及保存值的。
// Create an empty map with a key and value of type string
colors := map[string]string{}
// Add a few keys/value pairs to the map
colors["AliceBlue"] = "#F0F8FF"
colors["Coral"] = "#FF7F50"
colors["DarkGray"] = "#A9A9A9"
当我们向map添加数据的时候,总是给这个数据指定key,通过这个key,我们可以查找添加的数据,并且不需要遍历整个map。
fmt.Printf("Value: %s", colors["Coral"])
当我们遍历map的时候,得到的key-value的顺序不是固定的(译者注:即使在一次调用main函数的过程中,多次调用for-range,多次for-range的输出顺序也不是固定的,关于这点可以参考文献中的关于for-range的说明):
colors := map[string]string{}
colors["AliceBlue"] = "#F0F8FF"
colors["Coral"] = "#FF7F50"
colors["DarkGray"] = "#A9A9A9"
colors["ForestGreen"] = "#228B22"
colors["Indigo"] = "#4B0082"
colors["Lime"] = "#00FF00"
colors["Navy"] = "#000080"
colors["Orchid"] = "#DA70D6"
colors["Salmon"] = "#FA8072"
for key, value := range colors {
fmt.Printf("%s:%s, ", key, value)
}
下面是两组输出,可见遍历map的顺序确实不是固定的:
Coral:#FF7F50, DarkGray:#A9A9A9, Navy:#000080, Orchid:#DA70D6, AliceBlue:#F0F8FF, ForestGreen:#228B22,Indigo:#4B0082, Lime:#00FF00, Salmon:#FA8072,
Orchid:#DA70D6, Coral:#FF7F50, DarkGray:#A9A9A9, ForestGreen:#228B22, Navy:#000080, Salmon:#FA8072, AliceBlue:#F0F8FF, Indigo:#4B0082, Lime:#00FF00,
现在我们知道了map的创建、添加、以及遍历,现在尝试解开map的面纱。
map的结构
Map是通过hash table实现的,关于hash table已经有很多文章在介绍了,下面是维基百科:
http://en.wikipedia.org/wiki/Hash_table
用来实现golang的hash table是一个桶(bucket)的数组,桶的个数总是2的幂,当执行map操作的时候,比如colors["Black"] = "#000000",针对我们提供的key,会生成一个hash key,在我们的例子中”Black”用来生成hash key,生成的hash key的low order bits(LOB)部分会用来选择数组中的桶。
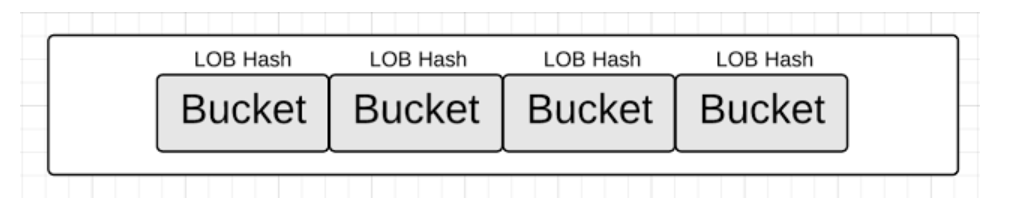 桶并锁定后,key/value对就可以被存储、删除或者查找,取决于操作的类型。如果我们查看bucket的内部实现,会发现两个数据结构。首先,有一个存储
桶并锁定后,key/value对就可以被存储、删除或者查找,取决于操作的类型。如果我们查看bucket的内部实现,会发现两个数据结构。首先,有一个存储high order bits(HOB)的字节数组数组,这里的HOB跟上面的LOB来自同一个hash key,这个数组用来区分存在同一个bucket中的不同的kay/value对(这个译者有疑问,待查证)。其次,有个字节数组来存储key/value对,在同一个bucket中,这个byte数组先存储所有的key,再存放所有的value。
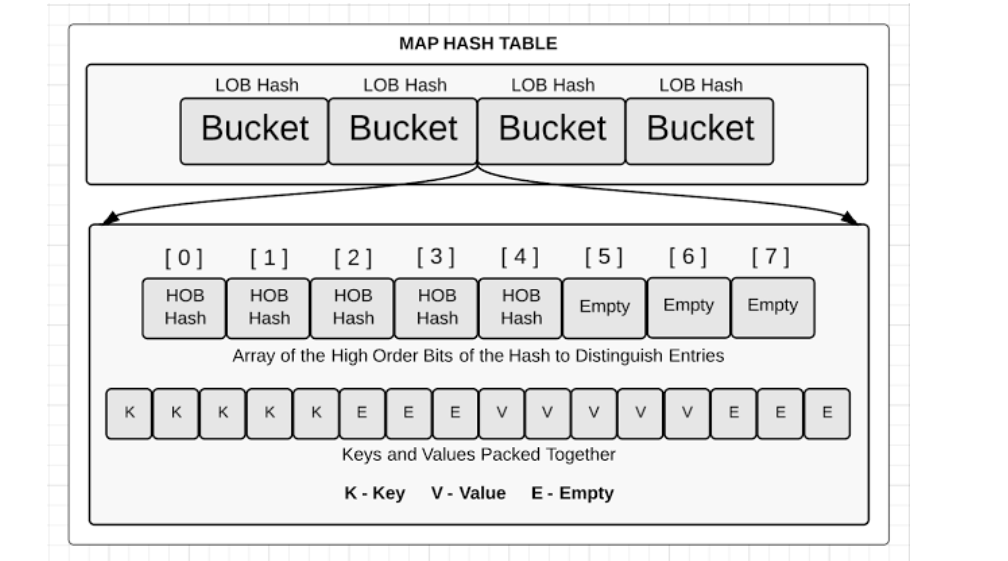 当我们遍历map的时候,迭代器遍历bucket数组,并返回在最终的byte数组中的key/value对,这就是为什么map不是有序的。hash key决定了map的遍历顺序,因为它决定了key/value对最终落在了哪个bucket中(译者注:这个地方没说清楚,参考浅谈Go语言实现原理 for-range,在使用for-range遍历map时,
当我们遍历map的时候,迭代器遍历bucket数组,并返回在最终的byte数组中的key/value对,这就是为什么map不是有序的。hash key决定了map的遍历顺序,因为它决定了key/value对最终落在了哪个bucket中(译者注:这个地方没说清楚,参考浅谈Go语言实现原理 for-range,在使用for-range遍历map时,mapiterinit会生成一个随机数,用来影响for-range开始的index,从而每次遍历顺序都是不同的,代码路径在src/runtime/map.go)。
内存以及Bucket溢出
在byte数组中,key/value依次排列是有原因的(指先排所有的key,再排所有的value),如果我们按照key/value/key/value的方式来排,为了保持边界对齐(maintain proper alignment boundaries),我们需要在每个key/value对之间添加很多填充字节(padding allocations),举例如下:
map[int64]int8
这个map中,value占一个字节,但为了边界对齐,需要在每个key/value对后面添加7个字节。通过将byte数组通过key/key/value/value的方式来排序key/value,我们只需在字节数组的最后来填充字节保持对齐,而不是在每个key/value之间,这样省了一笔内存开销。如果想要了解更多的关于字节对齐的细节,看下面博客:
http://www.goinggo.net/2013/07/understanding-type-in-go.html](http://www.goinggo.net/2013/07/understanding-type-in-go.html)
一个bucket被设计成最多存储8个key/value对,如果有第9个,需要创建一个overflow bucket,这个overflow bucket需要从原来的bucket访问(看下面的图)。
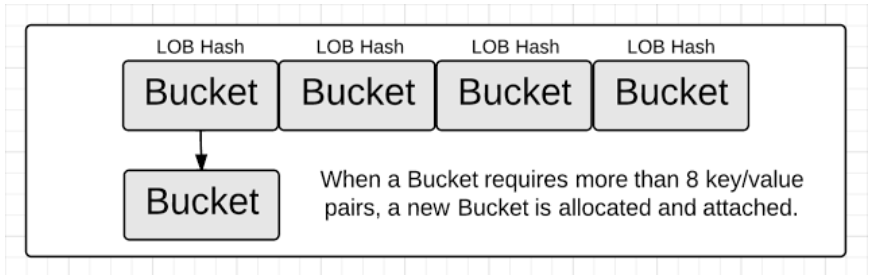 下面这个图转自博客浅谈go语言实现原理-map,也说明了这个事情。
下面这个图转自博客浅谈go语言实现原理-map,也说明了这个事情。
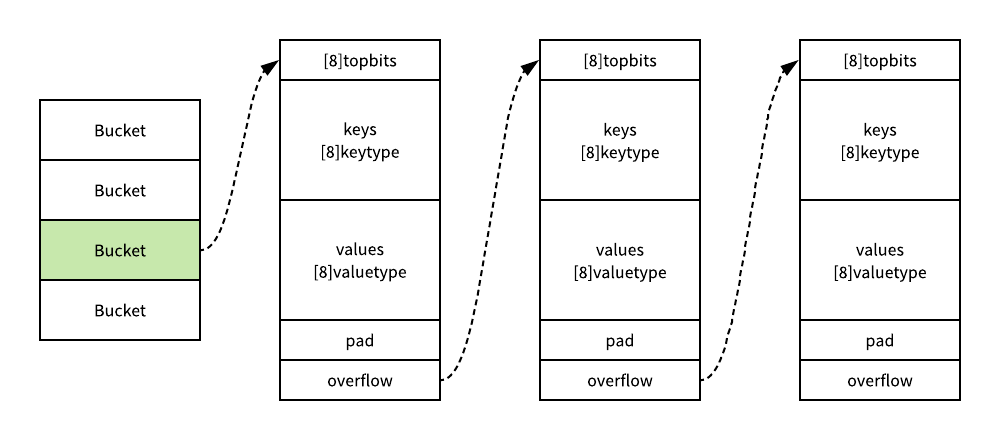
译者补充:map的数据结构在golang的src/runtime/map.go中,下面是golang1.12.7的源代码中map的结构:
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
其中B是用指数表示的,表示桶的个数,实际个数为2^B,oldbuckets表示在扩容时的旧bucket数组,不扩容时为nil。
译者补充:一个bucket是一大块内存,开始的8*8个字节为HOB字节数组,后面就是keykey…valuevalue…,访问key和value是通过偏移来实现的。下面图来自博客浅谈go语言实现原理-map
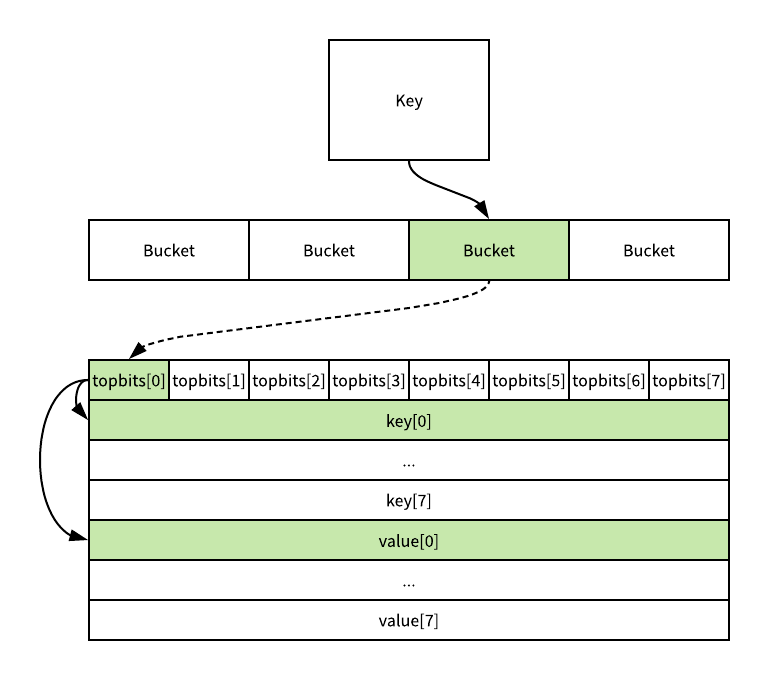
map是怎么扩展的
当我们持续在map中添加以及删除元素的时候,map的性能会变得恶化,用来决定map是否扩展的负载因子(load factor)取决于四个因素:
- % overflow : Percentage of buckets which have an overflow bucket
- bytes/entry : Number of overhead bytes used per key/value pair
- hitprobe : Number of entries that need to be checked when looking up a key
- missprobe : Number of entries that need to be checked when looking up an absent key
当前,golang使用下面的负载阈值:
| LOAD | %overflow | bytes/entry | hitprobe | missprobe |
|---|---|---|---|---|
| 6.50 | 20.9 | 10.79 | 4.52 | 6.50 |
扩展hash table的时候,首先会分配一个指向当前bucket的指针,称为old bucket。然后一个新的bucket会被分配,新分配的bucket的容量是当前bucket的两倍。这会导致大量内存分配,但是分配后并未初始化,所以还是挺快的。
当新的bucket可用的时候,旧的bucket中的key/value对会被移动或称为evacuated到新的bucket数组中。之前在同一个bucket中的key/value对,被移动到新的bucket之后,可能会处于不同的bucket中,evacuation算法倾向于将key/value对均匀地分布在数组中。
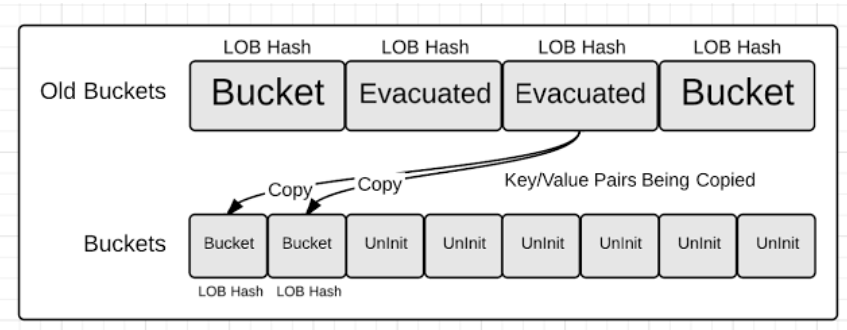 这些都是一些非常精巧的操作(delicate dance),因为在
这些都是一些非常精巧的操作(delicate dance),因为在evacuation操作完成之前,迭代操作仍然需要访问old array,同时这也会影响key/value的返回顺序,为了保证在扩展时,仍能迭代访问golang做了很多工作。
总结
正如我开头所说的,这只是map的结构以及增长的宏观视角,代码是用c实现的,并执行了很多内存以及指针操作来保证高效、安全。 显然,map的实现可能会变,但即使发生变化,保持对map的宏观认识并不是影响我们使用map的能力。至少,在你知道map会存放多少个key/value对时,可以在创建map的时候指定长度,来避免使用map的时候进行扩展;同时也解释了为什么map是无序的。