以SchedulerServer为例
SchedulerServer初始化了一个PodInformer,并启动、等待同步。查看一下这个标准流程。
s.PodInformer = factory.NewPodInformer(client, 0),
go s.PodInformer.Informer().Run(stop)
controller.WaitForCacheSync("scheduler", stop, s.PodInformer.Informer().HasSynced)
create
create方法调用的是factory的NewPodInformer方法,具体如下:
// NewPodInformer creates a shared index informer that returns only non-terminal pods.
func NewPodInformer(client clientset.Interface, resyncPeriod time.Duration) coreinformers.PodInformer {
// 设置List Watch的selector,pod的status.phase不能等于Succeeded,也不能等于Failed
selector := fields.ParseSelectorOrDie(
"status.phase!=" + string(v1.PodSucceeded) +
",status.phase!=" + string(v1.PodFailed))
// 创建一个ListWatch,包含以listFunc以及一个watchFunc,这两个方法就是调用Rest API进行了Get请求以及Watch请求,
// 这里的listFunc以及watchFunc,都设置了上述的FieldSelector,其功能类似于LabelSelector。
lw := cache.NewListWatchFromClient(client.CoreV1().RESTClient(), string(v1.ResourcePods), metav1.NamespaceAll, selector)
// 利用上述lw生成一个SharedIndexInformer,同时创建了一个Indexer,是个map类型,key为字符串"namespace",
// value是一个函数,这个函数返回一个[]string{},里面只有对象的namespace这样以一个元素,这个Indexer只关注pod的namespace
return &podInformer{
informer: cache.NewSharedIndexInformer(lw, &v1.Pod{}, resyncPeriod, cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc}),
}
}
上述NewShareIndexInformer的代码路径是vendor/k8s.io/client-go/tools/cache/shared_informer.go,返回的具体类型是sharedIndexInformer。
上述代码在初始化sharedIndexInformer时,顺便初始化了一个Indexer NewIndexer(DeletionHandlingMetaNamespaceKeyFunc, indexers)
indexer
indexer的概念非常绕,其代码路径在vendor/k8s.io/client-go/tools/cache/index.go。总结几点就是:
- 是个并发安全的缓存,自带一个锁,以及一个map,map的value是interface{}类型
- 带有索引,并且是一个类似于二级索引的形式
结构大概如下:
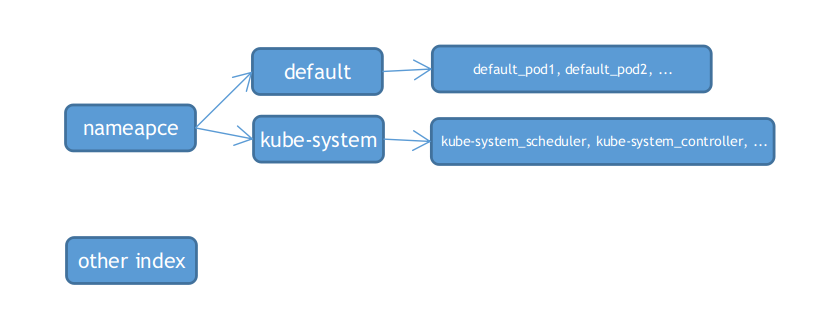
重要的定义如下:
// IndexFunc knows how to provide an indexed value for an object.
// 定义了一个函数,输入是一个object,输出是一个string slice,
type IndexFunc func(obj interface{}) ([]string, error)
// MetaNamespaceIndexFunc is a default index function that indexes based on an object's namespace
// 这个就是一个IndexFunc的定义,输入是pod,输出是包含这个pod的namespace的一个slice
func MetaNamespaceIndexFunc(obj interface{}) ([]string, error) {
meta, err := meta.Accessor(obj)
if err != nil {
return []string{""}, fmt.Errorf("object has no meta: %v", err)
}
return []string{meta.GetNamespace()}, nil
}
// 这个map的value是obj的KeyFunc产生的key,比如:default_pod1
// map的key是IndexFunc产生的索引,比如: default
type Index map[string]sets.String
// 这个比较好理解,是IndexFunc名字到IndexFunc定义的映射
type Indexers map[string]IndexFunc
// 这个map的key是索引的名字,比如namespace索引的“namespace”
type Indices map[string]Index
下面是索引的更新函数,Add操作以及Update操作都是引起索引的更新操作。
// updateIndices modifies the objects location in the managed indexes, if this is an update, you must provide an oldObj
// updateIndices must be called from a function that already has a lock on the cache
func (c *threadSafeMap) updateIndices(oldObj interface{}, newObj interface{}, key string) {
// if we got an old object, we need to remove it before we add it again
if oldObj != nil {
c.deleteFromIndices(oldObj, key)
}
// 这里只有一个indexer,name为namespace,key为获取obj namespace的函数
for name, indexFunc := range c.indexers {
// indexValues为一个slice,其只含有一个元素,即obj的namespace
indexValues, err := indexFunc(newObj)
if err != nil {
panic(fmt.Errorf("unable to calculate an index entry for key %q on index %q: %v", key, name, err))
}
// 初始化时,indices是空的,所以如果是add操作,这里的index是nil
index := c.indices[name]
if index == nil {
index = Index{}
// name为索引的名字,即字符串"namespace"
c.indices[name] = index
}
// indexValues是obj所在的namespace,比如"default",只有一个值
for _, indexValue := range indexValues {
set := index[indexValue]
if set == nil {
set = sets.String{}
index[indexValue] = set
}
// 这里的key为 "default-pod1"
set.Insert(key)
}
}
}
run
调用的就是sharedIndexInformer的run方法。run方法就是创建controller,进行缓存同步。
func (s *sharedIndexInformer) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
// FIFO是允许处理delete时间的Delta队列,是一个生产者-消费者队列
// 这里Reflector是生产者,任何调用Pop方法的都是消费者
// DeltaFIFO solves this use case:
// * You want to process every object change (delta) at most once.
// * When you process an object, you want to see everything
// that's happened to it since you last processed it.
// * You want to process the deletion of objects.
// * You might want to periodically reprocess objects.
fifo := NewDeltaFIFO(MetaNamespaceKeyFunc, nil, s.indexer)
cfg := &Config{
Queue: fifo,
ListerWatcher: s.listerWatcher,
ObjectType: s.objectType,
FullResyncPeriod: s.resyncCheckPeriod,
RetryOnError: false,
ShouldResync: s.processor.shouldResync,
Process: s.HandleDeltas,
}
func() {
s.startedLock.Lock()
defer s.startedLock.Unlock()
s.controller = New(cfg)
s.controller.(*controller).clock = s.clock
s.started = true
}()
// Separate stop channel because Processor should be stopped strictly after controller
processorStopCh := make(chan struct{})
var wg wait.Group
defer wg.Wait() // Wait for Processor to stop
defer close(processorStopCh) // Tell Processor to stop
wg.StartWithChannel(processorStopCh, s.cacheMutationDetector.Run)
wg.StartWithChannel(processorStopCh, s.processor.run)
defer func() {
s.startedLock.Lock()
defer s.startedLock.Unlock()
s.stopped = true // Don't want any new listeners
}()
s.controller.Run(stopCh)
}
sharedIndexInformer的WaitForCacheSync
字面意思是等待同步,那么到底是等待什么动作呢,上面的podInformer调用的是s.PodInformer.Informer().HasSynced,其最终调用的是下面方法:
func (s *sharedIndexInformer) HasSynced() bool {
s.startedLock.Lock()
defer s.startedLock.Unlock()
if s.controller == nil {
return false
}
return s.controller.HasSynced()
}
调用了controller的HasSynced方法
// Returns true once this controller has completed an initial resource listing
func (c *controller) HasSynced() bool {
这个Queue就是DeltaFIFO
return c.config.Queue.HasSynced()
}
继续看:
// 当DeltaFIFO的Add/Update/Delete/AddIfNotPresent方法被首次调用时,返回true,或者
// 或者当第一次调用Update,但是首次调用Replace时,所有插入的item,都已经被popped
func (f *DeltaFIFO) HasSynced() bool {
f.lock.Lock()
defer f.lock.Unlock()
return f.populated && f.initialPopulationCount == 0
}
关于这两个参数有注释:
// populated is true if the first batch of items inserted by Replace() has been populated
// or Delete/Add/Update was called first.
populated bool
// 第一次调用Replace()方法时,插入的items的数量。
initialPopulationCount int
总结来看,这里的HasSynced的意思就是是否将首次list的数据全部同步到cache,即全部从DeltaFIFO同步到Indexer。
reflector的ListAndWatch方法
关于reflector,reflector是主要向apiserver发送listwatch的组件,其run方法就是不断调用自身的ListAndWatch方法,
// Run starts a watch and handles watch events. Will restart the watch if it is closed.
// Run will exit when stopCh is closed.
func (r *Reflector) Run(stopCh <-chan struct{}) {
glog.V(3).Infof("Starting reflector %v (%s) from %s", r.expectedType, r.resyncPeriod, r.name)
wait.Until(func() {
if err := r.ListAndWatch(stopCh); err != nil {
utilruntime.HandleError(err)
}
}, r.period, stopCh)
}
其ListAndWatch方法比较长,不贴代码了,总结如下:
- 先list一遍所有的object,list的option中
ResourceVersion被设置为0 - 调用syncWith方法,用list到的object替换DeltaFIFO中的object,这里是调用Replace方法,这个方法会删除Delta之前的item,并且替换为当前的item。如果不会出现错误导致Reflector重新执行ListAndWatch,那么这个Replace只被调用一次,并且在调用时,设置initialPopulationCount为插入的item个数,并且每调用一次pop,这个数值会减1.
- 启动一个无限for循环,不断调用listWatcher的Watch方法,这个listWatcher就是在初始化SharedIndexInformer时提供的LW。
- 在这个for循环中,调用Watch后,根据Watch到的事件类型,更新到DeltaFIFO中,另外需要说一点如果是
UPDATE事件,跟ADD事件处理方式是一样的,只不过被标记为update
controller是怎么工作的
在上面的sharedIndexInformer的run方法中创建了一个controller,即informer机制中的controller,它的run方法如下:
// Run begins processing items, and will continue until a value is sent down stopCh.
// It's an error to call Run more than once.
// Run blocks; call via go.
func (c *controller) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
go func() {
<-stopCh
c.config.Queue.Close()
}()
r := NewReflector(
c.config.ListerWatcher,
c.config.ObjectType,
c.config.Queue,
c.config.FullResyncPeriod,
)
r.ShouldResync = c.config.ShouldResync
r.clock = c.clock
c.reflectorMutex.Lock()
c.reflector = r
c.reflectorMutex.Unlock()
var wg wait.Group
defer wg.Wait()
wg.StartWithChannel(stopCh, r.Run)
wait.Until(c.processLoop, time.Second, stopCh)
}
可以看出,是controller根据配置生成一个reflecter,并运行的,其processLoop就是不断调用DeltaFIFO的POP方法,并交给procsss function处理,这个的process function就是func (s *sharedIndexInformer) HandleDeltas(obj interface{}) error方法。
其实现如下:
func (s *sharedIndexInformer) HandleDeltas(obj interface{}) error {
s.blockDeltas.Lock()
defer s.blockDeltas.Unlock()
// from oldest to newest
for _, d := range obj.(Deltas) {
switch d.Type {
case Sync, Added, Updated:
isSync := d.Type == Sync
s.cacheMutationDetector.AddObject(d.Object)
if old, exists, err := s.indexer.Get(d.Object); err == nil && exists {
if err := s.indexer.Update(d.Object); err != nil {
return err
}
s.processor.distribute(updateNotification{oldObj: old, newObj: d.Object}, isSync)
} else {
if err := s.indexer.Add(d.Object); err != nil {
return err
}
s.processor.distribute(addNotification{newObj: d.Object}, isSync)
}
case Deleted:
// 这里的Delete是会真的从indexer中删除的。
if err := s.indexer.Delete(d.Object); err != nil {
return err
}
// 交给事件处理器(用户注册的)
s.processor.distribute(deleteNotification{oldObj: d.Object}, false)
}
}
return nil
}
上面介绍的内容,可以用下图来表示:
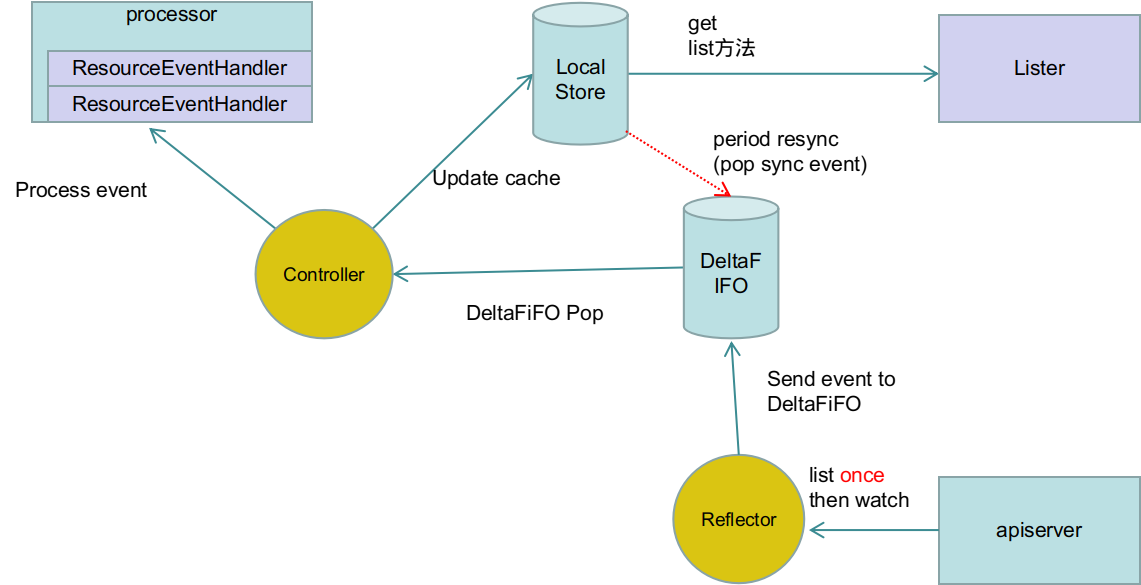
关于SharedInformer
多个controller共用一个informer,每个controller注册自己的ResourceEventHandler,这样做的好处是:
- 减少缓存使用
- 减少与apiserver的连接数(watch )
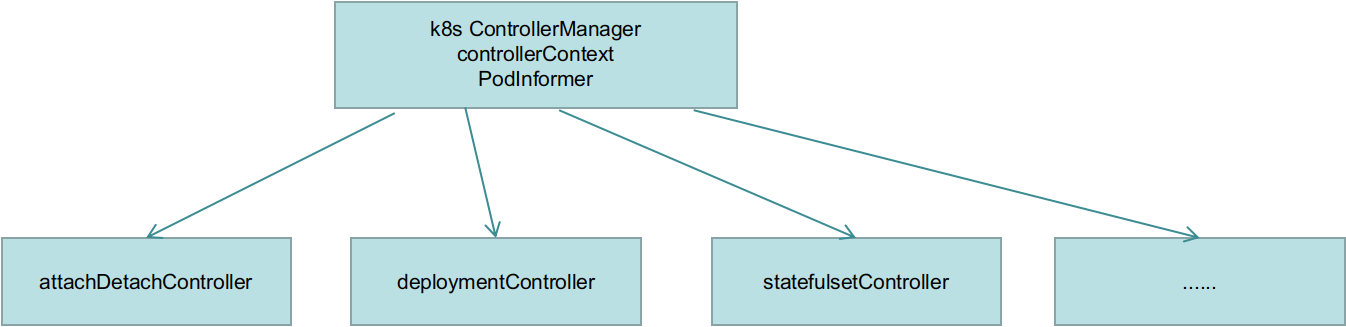
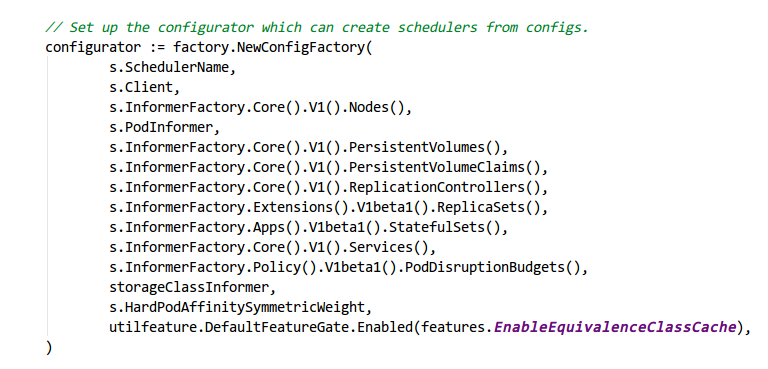
关于SharedInformerFactory,一个SharedInformer的工厂模式,生成特定资源的informer,以k8s scheduler的configFactory为例
watch是怎么实现的
HTTP/1.1则规定所有连接都必须是持久的,除非显式地在头部加上Connection: close,另外HTTP/1.1支持分块编码机制,在头部加入Transfer-Encoding: chunked 之后,就代表这个报文采用了分块编码,在分块编码传输中,每次发送数据之前会先发送数据的长度,然后再发送数据,如果发送的数据长度为0,就表示这次传输结束了。
那watch机制也是靠这个实现的。具体来说,就是watch api与apiserver维持一个长连接,apiserver在一次发送数据之前先发送数据长度。apiserver中的代码大致是如此的,但是没有具体研究。
k8s中WatchServer的目录文件kubernetes/staging/src/k8s.io/apiserver/pkg/endpoints/handlers/watch.go,里面有如下代码:
// begin the stream
w.Header().Set("Content-Type", s.MediaType)
w.Header().Set("Transfer-Encoding", "chunked")
w.WriteHeader(http.StatusOK)
另外,需要注意,Chunked transfer encoding仅仅在HTTP/1.1中使用的,HTTP/2是不支持的,HTTP/2提供了自己的流的实现,这个可以参考Chunked transfer encoding
2020.9.9补充: 对golang来说,chunk是默认支持的,发送请求的时候没有没有特别,服务端可以选择以chunk的形式返回,如果是这样,golang的resp.Body也是自动deChunk的。参考:
// Body represents the response body.
//
// The response body is streamed on demand as the Body field
// is read. If the network connection fails or the server
// terminates the response, Body.Read calls return an error.
//
// The http Client and Transport guarantee that Body is always
// non-nil, even on responses without a body or responses with
// a zero-length body. It is the caller's responsibility to
// close Body. The default HTTP client's Transport may not
// reuse HTTP/1.x "keep-alive" TCP connections if the Body is
// not read to completion and closed.
//
// The Body is automatically dechunked if the server replied
// with a "chunked" Transfer-Encoding.
//
// As of Go 1.12, the Body will also implement io.Writer
// on a successful "101 Switching Protocols" response,
// as used by WebSockets and HTTP/2's "h2c" mode.
Body io.ReadCloser
K8s watch的实现代码在:k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/watch/streamwatcher.go
func (r *Request) WatchWithSpecificDecoders(wrapperDecoderFn func(io.ReadCloser) streaming.Decoder, embeddedDecoder runtime.Decoder) (watch.Interface, error) {
// We specifically don't want to rate limit watches, so we
// don't use r.throttle here.
if r.err != nil {
return nil, r.err
}
if r.serializers.Framer == nil {
return nil, fmt.Errorf("watching resources is not possible with this client (content-type: %s)", r.content.ContentType)
}
url := r.URL().String()
req, err := http.NewRequest(r.verb, url, r.body)
if err != nil {
return nil, err
}
if r.ctx != nil {
req = req.WithContext(r.ctx)
}
req.Header = r.headers
client := r.client
if client == nil {
client = http.DefaultClient
}
r.backoffMgr.Sleep(r.backoffMgr.CalculateBackoff(r.URL()))
resp, err := client.Do(req)
updateURLMetrics(r, resp, err)
if r.baseURL != nil {
if err != nil {
r.backoffMgr.UpdateBackoff(r.baseURL, err, 0)
} else {
r.backoffMgr.UpdateBackoff(r.baseURL, err, resp.StatusCode)
}
}
if err != nil {
// The watch stream mechanism handles many common partial data errors, so closed
// connections can be retried in many cases.
if net.IsProbableEOF(err) {
return watch.NewEmptyWatch(), nil
}
return nil, err
}
if resp.StatusCode != http.StatusOK {
defer resp.Body.Close()
if result := r.transformResponse(resp, req); result.err != nil {
return nil, result.err
}
return nil, fmt.Errorf("for request '%+v', got status: %v", url, resp.StatusCode)
}
wrapperDecoder := wrapperDecoderFn(resp.Body)
return watch.NewStreamWatcher(restclientwatch.NewDecoder(wrapperDecoder, embeddedDecoder)), nil
}
// NewStreamWatcher creates a StreamWatcher from the given decoder.
func NewStreamWatcher(d Decoder) *StreamWatcher {
sw := &StreamWatcher{
source: d,
// It's easy for a consumer to add buffering via an extra
// goroutine/channel, but impossible for them to remove it,
// so nonbuffered is better.
result: make(chan Event),
}
go sw.receive()
return sw
}
2022.4.29 补充:
Http2 并不是使用 Chunked Transfer Encoding,引入了以 Frame 为单位来进行传输。client-go 具体是使用 http1.1 还是 http2,是有一个协商过程的,这个可以查下 ALPN(Application-Layer Protocol negotiation)。
具体参考K8s 如何提供更高效稳定的编排能力?K8s Watch 实现机制浅析
参考: