目录
K8s调度器的SchedulerCache是其工作的核心,用来缓存所有已经调度过的pod,这些pod按照Node来进行划分,每个Node包含一个NodeInfo,包含一个该节点上的所有的pod。本文基于K8s1.14分析下SchedulerCache涉及到的一些东西。
Cache State Machine
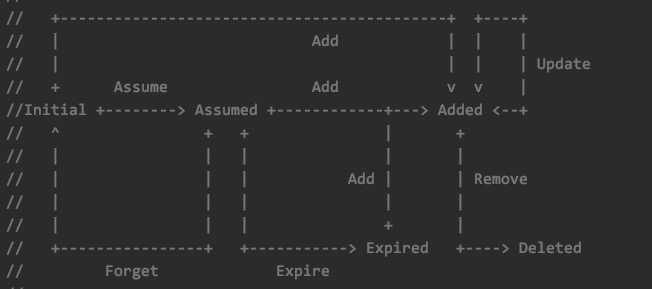
下面这个图是scheduler在internal/cache/interface.go文件中给出的,将pod的状态分为Initial,Assumed,Added,Expired,Deleted等。其中Initial,Expired,Deleted状态的pod是不会存在在cache中的。对于pod的状态有一些假设:
- 不会有pod被assume两次
- 一个pod可以被添加到cache中,但是此pod不经过调度器,这种情况下,会有Add操作,但是没有Assume操作。
- 如果pod没有被Add,就不会被removed以及updated
Expired,Deleted都是合法的结束状态,比如由于网络问题,pod在改变了自身状态时(被add或者delete),事件没有通知到cache
基于上面描述,SchedulerCache中存在AssumedPods以及AddedPods两类pod的集合,我们看一下这两个集合是如何更新的。
schedulerCache 结构体及其 Cache 接口实现
Cache接口的定义也在interface.go文件中,该接口的实现就是schedulerCache结构体,该结构体如下:
type schedulerCache struct {
stop <-chan struct{}
ttl time.Duration
period time.Duration
mu sync.RWMutex
// assumed pod的集合,只是名字的集合,需要用这些名字来查询podStates cache
assumedPods map[string]bool
podStates map[string]*podState
nodes map[string]*nodeInfoListItem
// 双向链表的头指针,指向最新更新的NodeInfo
headNode *nodeInfoListItem
nodeTree *NodeTree
imageStates map[string]*imageState
}
type podState struct {
pod *v1.Pod
// assumedPod通过这个deadline来决定是否失效
deadline *time.Time
// 如果bind还没有完成,阻止cache对assumedPod失效
bindingFinished bool
}
type nodeInfoListItem struct {
info *schedulernodeinfo.NodeInfo
next *nodeInfoListItem
prev *nodeInfoListItem
}
这里有个问题,pod什么时候会出现在assumedPods集合中,什么时候会出现在podStates集合中?(根据下面代码分析,可以得出的结论是如果在assumedPods集合中,一定在podStates集合中。对于未经过assume的Add事件,Pod nodeName字段不为空,是不会出现在assume集合中的)
SchedulerCache实现接口的代码比较多,这里只是介绍重点几个。后面会结合上面的状态机看一下pod的状态转换。
// AssumePod操作有几个步骤是必做的:
// 1. 添加到NodeInfo中,减去对应资源
// 2. 添加到podStates集合中
// 3. 添加到assumedPods集合中
func (cache *schedulerCache) AssumePod(pod *v1.Pod) error {
// 已经assume过的不能再assume
if _, ok := cache.podStates[key]; ok {
return fmt.Errorf("pod %v is in the cache, so can't be assumed", key)
}
// 这个是添加到pod.spec.nodeName所指的Node的NodeInfo中,并减去相关资源
cache.addPod(pod)
ps := &podState{
pod: pod,
}
// 添加到podStates
cache.podStates[key] = ps
// 添加都assumedPods
cache.assumedPods[key] = true
return nil
}
// FinishBinding不会对任何缓存集合进行添加或删除操作,只是在assume集合中存在pod的时候,给其设置deadline
func (cache *schedulerCache) finishBinding(pod *v1.Pod, now time.Time) error {
currState, ok := cache.podStates[key]
// 如果podStates和assumedPods都存在此pod,则设置bindingFinished为,并设置deadline
if ok && cache.assumedPods[key] {
dl := now.Add(cache.ttl)
currState.bindingFinished = true
currState.deadline = &dl
}
return nil
}
// ForgetPod会从SchedulerCache中完全删除pod
func (cache *schedulerCache) ForgetPod(pod *v1.Pod) error {
currState, ok := cache.podStates[key]
// 比较内存中的和参数中的pod的NodeName是否一致,如果不一致,则报错
if ok && currState.pod.Spec.NodeName != pod.Spec.NodeName {
return fmt.Errorf("pod %v was assumed on %v but assigned to %v", key, pod.Spec.NodeName, currState.pod.Spec.NodeName)
}
switch {
// 只有在assumedPods集合中的pod才能被Forget
case ok && cache.assumedPods[key]:
// 从NodeInfo中删除资源
err := cache.removePod(pod)
if err != nil {
return err
}
// 从集合中删除
delete(cache.assumedPods, key)
delete(cache.podStates, key)
default:
return fmt.Errorf("pod %v wasn't assumed so cannot be forgotten", key)
}
return nil
}
// Scheduler的Pod Add event handler是这个方法调用的唯一入口(这个event handler有个过滤规则是pod的NodeName必须不为空)
func (cache *schedulerCache) AddPod(pod *v1.Pod) error {
currState, ok := cache.podStates[key]
switch {
// 在podState和assumePod中都已经存在
case ok && cache.assumedPods[key]:
if currState.pod.Spec.NodeName != pod.Spec.NodeName {
// 如果节点换了,移除旧的,添加新的
cache.removePod(currState.pod)
cache.addPod(pod)
}
// 从assumePod集合中删除,收到pod的添加事件,并且pod存在在assumepodcache中的时候,会从assumedpodcache中删除pod
delete(cache.assumedPods, key)
cache.podStates[key].deadline = nil
cache.podStates[key].pod = pod
case !ok:
// 在podStates中没有,添加进去,之前失效了,那这个时候assumePod集合中在不在呢?
cache.addPod(pod)
ps := &podState{
pod: pod,
}
cache.podStates[key] = ps
default:
return fmt.Errorf("pod %v was already in added state", key)
}
return nil
}
// Scheduler的pod Update event handler是这个方法的唯一入口,(带有过滤规则的)
func (cache *schedulerCache) UpdatePod(oldPod, newPod *v1.Pod) error {
currState, ok := cache.podStates[key]
switch {
// An assumed pod won't have Update/Remove event. It needs to have Add event
// before Update event, in which case the state would change from Assumed to Added.
// 在podStates中,但是不在assumedPod中
case ok && !cache.assumedPods[key]:
if currState.pod.Spec.NodeName != newPod.Spec.NodeName {
// pod更新之后,nodeName变了,scheduler直接崩掉,不会发生
klog.Errorf("Pod %v updated on a different node than previously added to.", key)
klog.Fatalf("Schedulercache is corrupted and can badly affect scheduling decisions")
}
// 更新nodeInfo,对于新旧两个pod,更新操作就是无脑删除旧的,添加新的
if err := cache.updatePod(oldPod, newPod); err != nil {
return err
}
// updatePod会完全将旧的pod更新为新的pod,如果assumePod时,额外添加了新的信息,可能在
// updatePod时被覆盖
currState.pod = newPod
default:
return fmt.Errorf("pod %v is not added to scheduler cache, so cannot be updated", key)
}
return nil
}
func (cache *schedulerCache) RemovePod(pod *v1.Pod) error {
currState, ok := cache.podStates[key]
switch {
// An assumed pod won't have Delete/Remove event. It needs to have Add event
// before Remove event, in which case the state would change from Assumed to Added.
// 在podState中,但是不在assumePod中
case ok && !cache.assumedPods[key]:
if currState.pod.Spec.NodeName != pod.Spec.NodeName {
// 崩
klog.Fatalf("Schedulercache is corrupted and can badly affect scheduling decisions")
}
// 从nodeInfo中删除
err := cache.removePod(currState.pod)
if err != nil {
return err
}
delete(cache.podStates, key)
default:
return fmt.Errorf("pod %v is not found in scheduler cache, so cannot be removed from it", key)
}
return nil
}
func (cache *schedulerCache) IsAssumedPod(pod *v1.Pod) (bool, error) {
// 判断是不是assumedpod的依据是不是在assume集合中。
b, found := cache.assumedPods[key]
if !found {
return false, nil
}
return b, nil
}
清空 Assume 过期的 Pod
在初始化SchedulerCache的时候,还启动了一个单独的goroutine,来执行AssumedPod的清理工作,整个goroutine的代码如下:
func (cache *schedulerCache) run() {
// 启动goroutine
go wait.Until(cache.cleanupExpiredAssumedPods, cache.period, cache.stop)
}
func (cache *schedulerCache) cleanupExpiredAssumedPods() {
cache.cleanupAssumedPods(time.Now())
}
// cleanupAssumedPods exists for making test deterministic by taking time as input argument.
func (cache *schedulerCache) cleanupAssumedPods(now time.Time) {
cache.mu.Lock()
defer cache.mu.Unlock()
// 遍历assumedPod集合,(The size of assumedPods should be small)
for key := range cache.assumedPods {
ps, ok := cache.podStates[key]
if !ok {
// 基于此path,如果pod在assumedPods集合中,那么pod一定在podStates集合中,但是在SchedulerCache的接口实现中
// 有很多实现在判断Pod是不是同时在这两个集合中
panic("Key found in assumed set but not in podStates. Potentially a logical error.")
}
if !ps.bindingFinished {
// 如果binding还没有结束,则不进行清理
continue
}
if now.After(*ps.deadline) {
// 过期了,执行清理操作,从所有cache的集合中删除pod
if err := cache.expirePod(key, ps); err != nil {
klog.Errorf("ExpirePod failed for %s: %v", key, err)
}
}
}
}
// 清理操作,从所有cache中清理pod
func (cache *schedulerCache) expirePod(key string, ps *podState) error {
if err := cache.removePod(ps.pod); err != nil {
return err
}
delete(cache.assumedPods, key)
delete(cache.podStates, key)
return nil
}