前段时间集群内的 elastic-operator 一直报错,报错跟下面类似,都是报 Too large resource version 的问题。记录下排查过程和相关知识点。
E0513 19:45:35.671005 598 reflector.go:178] object-"kube-system"/"kube-router-token-4px26": Failed to list *v1.Secret: Timeout: Too large resource version: 159128021, current: 159127032
I0513 19:46:05.472918 598 trace.go:116] Trace[308823067]: "Reflector ListAndWatch" name:object-"kube-system"/"default-token-h8dz9" (started: 2020-05-13 19:45:26.359131486 +0000 UTC m=+82049.527867341) (total time: 39.113684635s):
Trace[308823067]: [39.113684635s] [39.113684635s] END
E0513 19:46:05.473007 598 reflector.go:178] object-"kube-system"/"default-token-h8dz9": Failed to list *v1.Secret: Timeout: Too large resource version: 159128021, current: 159127032
这个报错,是 K8s informer 中的 reflector 去 list apiserver 时报的错误,错误是 apiserver 报出来的,并反馈给了 list 的客户端 reflector。下面分别从 apiserver 端以及 reflector 端分析这个错误。 这个错误存在对应的 github issue:Fix bug in reflector not recovering from “Too large resource version”… #92537,本文也是通过这个 issue 理解整个过程。
Apiserver 缓存层
在 kube-apiserver 的设计中,存在一个存储层,所有资源的 RESTful 请求都会传递到这个存储层进行处理,这个存储层的通用定义是 Storage.Interface,位于代码文件kubernetes/staging/src/k8s.io/apiserver/pkg/storage/interfaces.go中。其代码定义在下面。这个接口的实现有两个:
- underlyingStorage (rawStorage):对 etcd 的直接封装,将 etcd 作为存储层,这个封装是不带缓存的,所有的 crud 操作都是直接操作的 etcd。
- cacherStorage: 带缓存的存储层,这个是对 UnderlyingStorage 的封装,对于一些读操作,比如get/list 等,如果对数据的一致性要求不高(resourceVersion不为空,设置为0,或者设置为了特定值),可以从缓存中读取,避免请求 etcd。这个 CacheStorage 的实现是一个 Cache 结构体,在
kubernetes/staging/src/k8s.io/apiserver/pkg/storage/cacher/cacher.go文件中。
type Interface interface {
Versioner() Versioner
Create(ctx context.Context, key string, obj, out runtime.Object, ttl uint64) error
Delete(ctx context.Context, key string, out runtime.Object, preconditions *Preconditions, validateDeletion ValidateObjectFunc) error
Watch(ctx context.Context, key string, resourceVersion string, p SelectionPredicate) (watch.Interface, error)
WatchList(ctx context.Context, key string, resourceVersion string, p SelectionPredicate) (watch.Interface, error)
Get(ctx context.Context, key string, resourceVersion string, objPtr runtime.Object, ignoreNotFound bool) error
GetToList(ctx context.Context, key string, resourceVersion string, p SelectionPredicate, listObj runtime.Object) error
// 分析 too large resource version 问题,我们只关注 List 方法
List(ctx context.Context, key string, resourceVersion string, p SelectionPredicate, listObj runtime.Object) error
GuaranteedUpdate(
ctx context.Context, key string, ptrToType runtime.Object, ignoreNotFound bool,
precondtions *Preconditions, tryUpdate UpdateFunc, suggestion ...runtime.Object) error
Count(key string) (int64, error)
}
对于这个错误,因为我们发出的是 list 请求(reflector 的工作原理是先发一遍 list 请求,然后根据返回的 resourceVersion 进行 watch),而且apiserver默认是先访问缓存层的,所以我们直接看 CacheStorage 的 List 方法。这个方法的的参数中存在一个 resourceVersion,表示返回的数据至少要比 resourceVersion 要新。下面是 Cacher 结果题对于 List 的实现,我们只关注核心几行代码,
// List implements storage.Interface.
func (c *Cacher) List(ctx context.Context, key string, resourceVersion string, pred storage.SelectionPredicate, listObj runtime.Object) error {
// ... 省去部分代码
// 等待资源更新到特定的 resourceVersion
objs, readResourceVersion, err := c.watchCache.WaitUntilFreshAndList(listRV, trace)
if err != nil {
return err
}
// ... 省去部分代码
return nil
}
// 等待资源更新,并list
func (w *watchCache) WaitUntilFreshAndList(resourceVersion uint64, trace *utiltrace.Trace) ([]interface{}, uint64, error) {
err := w.waitUntilFreshAndBlock(resourceVersion, trace)
defer w.RUnlock()
if err != nil {
return nil, 0, err
}
return w.store.List(), w.resourceVersion, nil
}
// 阻塞等待资源更新到特定的 resourceVersion
func (w *watchCache) waitUntilFreshAndBlock(resourceVersion uint64, trace *utiltrace.Trace) error {
startTime := w.clock.Now()
go func() {
// blockTimeout 默认是是 3s
<-w.clock.After(blockTimeout)
w.cond.Broadcast()
}()
w.RLock()
// 如果等待了三秒,watchCache 的resourceVersion 还没有追赶上来,就会报 Too large resource version 错误。
for w.resourceVersion < resourceVersion {
if w.clock.Since(startTime) >= blockTimeout {
// Timeout with retry after 1 second.
return errors.NewTimeoutError(fmt.Sprintf("Too large resource version: %v, current: %v", resourceVersion, w.resourceVersion), 1)
}
w.cond.Wait()
}
return nil
}
通过上面 apiserver 的代码能看到,报错的原因是 apiserver 中 watchCache 的 resourceVersion 在收到请求的三秒内一直小于 list 请求传递过来的 resourceVersion,这个现象有点难解释,有可能的原因有:1)apiserver 发生了重启?但是 resourceVersion 没有赶上来?2)client-go 发出的 list 请求中间重新路由了 apiserver,并且几个 apiserver 的 rv 可能不一致?这几个case官方也没有明确说明,但是解决这个问题不是很难。Fix bug in reflector not recovering from “Too large resource version”… #92537这个 PR 更新了一下 reflector 的实现,如果收到了 Too large resource version 错误,重新 list 的时候,将 listOption 中的 resourceVersion 设置为 ““,这样每次list时都会透传 etcd。
Reflector 感知 Too large resource version 错误
我们看下这个PR Fix bug in reflector not recovering from “Too large resource version”… #92537是如何修复这个问题的。
思路其实也比较简单,就是新定义了一个错误类型ResourceVersionTooLarge,并且在收到这个错误的时候,设置下一次 list 操作的resourceVersion为”“,
首先是将 expiredError 和 tooLargeRV 错误都归结为一个错误:上次list的RV不可用,对于 expiredError,我们之前介绍过,其实就是 410 (Gone) 错误,也就是 too old resource version错误,遇到这两个错误的处理方式一致。
 遇到上述两个错误时,通过 setIsLastSyncResourceVersionUnavailable 设置不可用标志。
遇到上述两个错误时,通过 setIsLastSyncResourceVersionUnavailable 设置不可用标志。
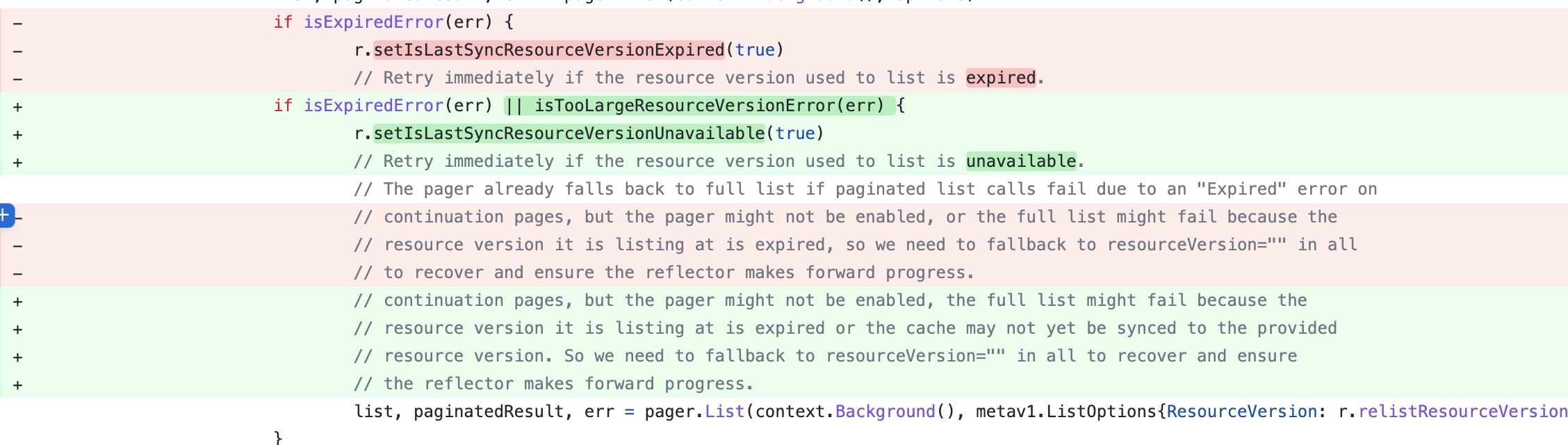 这样在下次重新 relist 的时候,一看设置了上次不可用的标志,就从最新的资源开始 relist,也就是透传 etcd,不走 cache了,这样就不会有问题了。
这样在下次重新 relist 的时候,一看设置了上次不可用的标志,就从最新的资源开始 relist,也就是透传 etcd,不走 cache了,这样就不会有问题了。
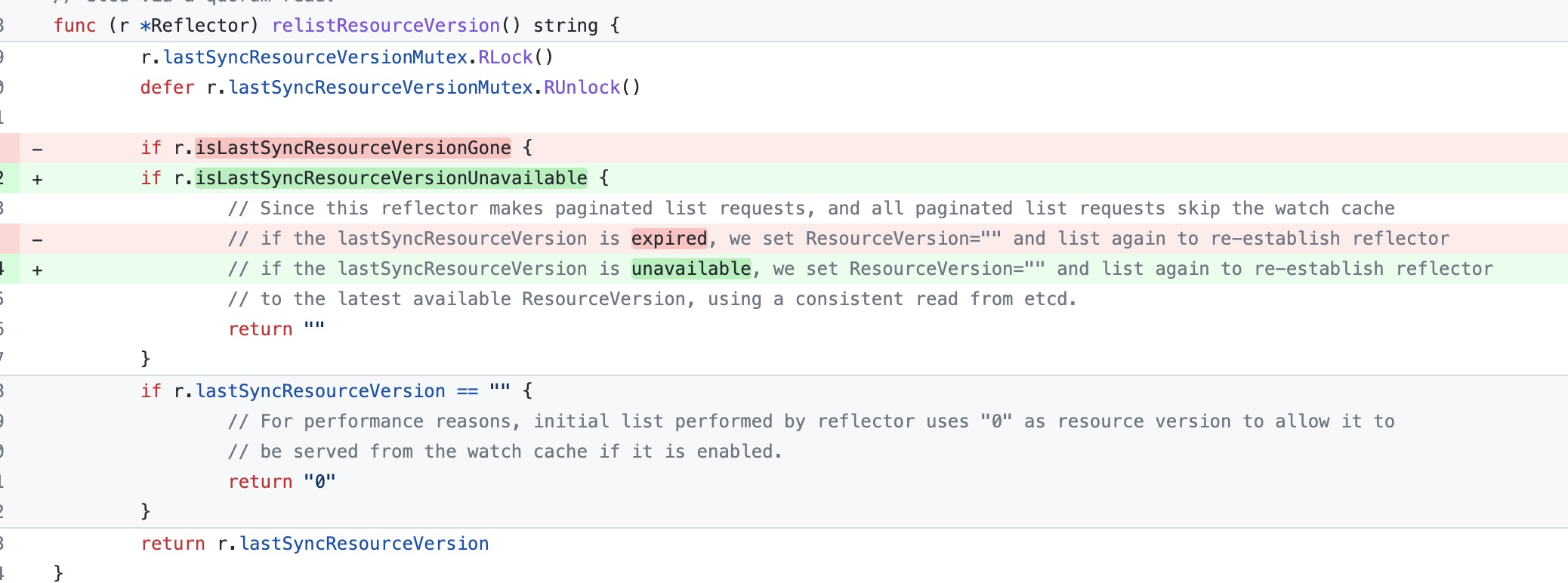
其实在实际情况中,我们不要拘泥于具体 K8s 版本,看一下具体的 reflector 实现就好了,也就是 client-go 的版本,因为在 K8s1.16 的client-go 中是不会有这个问题的,在出问题的 reflector 中每次全量list 时,resourceVersion 都是根据方法 relistResourceVersion 定的。
options := metav1.ListOptions{ResourceVersion: r.relistResourceVersion()}
而在我们K8s 1.16 的版本中,每次全量 list 时,设置的 ResourceVersion 都是0,这样也是没有问题的,如果设置了 ResourceVersion 为0,则对资源的版本没有要求,cache中存在什么版本就返回什么版本就好了。下面是 K8s 1.16 的实现:
// Explicitly set "0" as resource version - it's fine for the List()
// to be served from cache and potentially be delayed relative to
// etcd contents. Reflector framework will catch up via Watch() eventually.
options := metav1.ListOptions{ResourceVersion: "0"}