回顾一下常见的 too old resource version 问题,该报错错误信息如下,其中 1785219 是请求带过去的 rv(resource version),1787027 是 apiserver 缓存中最新的 rv,本文基于的 K8s 版本是 K8s1.16。
[kubelet] E0225 18:46:00.688601 62642 reflector.go:227] pkg/kubelet/config/apiserver.go:43: Failed to watch *api.Pod: too old resource version: 1785219 (1787027)
本文重点是看下为什么会有这个问题,什么场景下会发生,问题的现象和解决方式相对简单。
官方文档中的解释
《Efficient detection of changes》中说,kube-apiserver 只保留特定数量的历史数据,如果客户端进行 watch 请求时,携带的 rv 比当前保存的所有历史数据的最小值还小,则会有返回 410 Gone 错误,也就是 too old resource version 或者 ExpiredError。根据我们在《Apiserver 中缓存层 Cacher 的实现》的分析,apiserver 中历史窗口的大小默认为 100。
同时 etcd 在 MVCC 中保存历史数据时,也会只保留特定时间段的,或者保留特定数量的历史数据,具体是通过下面两个 flag 确定的。
- –auto-compaction-mode:可以配置成
periodic或者revision,分别表示使用周期性压缩,或者按版本号压缩,。 - –auto-compaction-retention 配置为 periodic 时,为周期性压缩保留的时间周期,比如 1h。auto-compaction-mode 为 revision 时,auto-compaction-retention 为保留的历史版本号数,比如 10000。
在官方文档中说,调用 watch 请求的时候,客户端应该具有感知到 410 Gone 错误的能力,当收到这个错误的时候,要重新执行一遍 list 操作,以获取最新的版本号。
bookmarks 机制
bookmark 机制的引入是为了缓解上面提到的历史窗口有限的问题的,其工作原理就是 apiserver 会定期发送一个 bookmark 事件给 watch 客户端,这个事件的类型为 BOOKMARK,并且只包含一个 rv,没有其他信息。目的是通知客户端当前 rv 的进度,防止客户端 watch 的资源一直没有发生更新,收不到事件,导致 rv 一直没有更新,这样在重新 watch 的时候,发送旧的 rv 给 apiserver。
bookmark 的实现在缓存层的 cacher 中,具体可以参考《Apiserver 中缓存层 Cacher 的实现》,本文不再详细描述。
官方文档对于 too old rv 问题只有简单的描述,似乎是理解了,但是看代码的时候其实还是有点疑惑,看文章后面分析~
Apiserver 缓存层的实现
这个比较简单,我们一两句概括下,就是在处理 watch 请求的时候,发现 watch 请求携带的 rv,比窗口中的最旧的还小,就报错。相关实现参考《Apiserver 中缓存层 Cacher 的实现》
func (w *watchCache) GetAllEventsSinceThreadUnsafe(resourceVersion uint64) ([]*watchCacheEvent, error) {
size := w.endIndex - w.startIndex
// 寻找最旧的 rv,最旧的 rv 也就是最小的 rv。
var oldest uint64
switch {
case size >= w.capacity:
oldest = w.cache[w.startIndex%w.capacity].ResourceVersion
case w.listResourceVersion > 0:
oldest = w.listResourceVersion + 1
case size > 0:
oldest = w.cache[w.startIndex%w.capacity].ResourceVersion
default:
return nil, fmt.Errorf("watch cache isn't correctly initialized")
}
// 携带的 rv 比当前最小的 rv 还小,就报错。
if resourceVersion < oldest-1 {
return nil, errors.NewGone(fmt.Sprintf("too old resource version: %d (%d)", resourceVersion, oldest-1))
}
// 省去其他代码...
return result, nil
}
我们重点思考下,为什么会有 too old rv 的问题,也就是什么情况下会发生。
相关 github issue
关于 too old rv 问题,有几个相关 issue:
- Sporadic “too old resource version” errors from master pods #22024,概括来说这个 issue 说问题是正常的,因为历史窗口大小是一定的,还有些细节问题,比如建议将日志级别从 error 改为 warning 等。
- “error that is not an unversioned.Status: too old resource version” #22830,这个 issue 时间比较久了,其大致意思是出现了未知错误,有可能不是期望的类型,或是 etcd 的错误不小心透传出来了。我们按照最新的 K8s 版本理解下这个问题,apiserver 在处理错误时,对于能感知到的错误,返回的都是
StatusError类型,也就是对错误进行了封装,(报错中的 unversioned.Status 结构对应下面代码中的metav1.Status)。该类型实现了statusError接口,如果在处理 rest 请求时返回的不是这个类型的错误,就会报上面错误日志。// 位于文件:k8s.io/apimachinery/pkg/api/errors/errors.go // StatusError is an error intended for consumption by a REST API server; it can also be // reconstructed by clients from a REST response. Public to allow easy type switches. type StatusError struct { ErrStatus metav1.Status } // 位于文件:staging/src/k8s.io/apiserver/pkg/endpoints/handlers/responsewriters/status.go type statusError interface { Status() metav1.Status }对于这个 too old resource version 问题,刚开始返回的错误应该是用 fmt.Errorf 生成的,参考Making error “too old resource version” a NewInternalError #15107

- change the “too old resource version” error from NewInternalError to NewBadRequest #16628,这个是将
too old rv问题的错误码定义成了410 Gone,觉得 InteralError 不合适。
相关的 issue 也是说正常的,需要添加文档来提醒用户这件事,我们还是研究下源码吧。
为什么会有 too old rv 问题
官方文档说的没错,因为历史窗口太小了,watch 请求的 rv 太旧了就会有这个问题。那我们思考一下为什么会出现 rv 太旧的情况。其中有一个比较明显且特别容易理解的 case:我发送一个单独的 watch 请求,并且指定这个 watch 请求的 rv 特别小,那就会出现这个问题,但在编码过程中,我们很少自己发送 watch 请求(也可能是我见识太少了),一般是通过 reflector 来实现,而 reflector 在发送 watch 请求之前都会发送一遍 list 请求,list 拿到的 rv 是最新的,然后再通过这个 rv 来执行 watch 请求,为什么我们有了最新的 rv,还会报 too old 的问题呢?
我们再看下 reflector 的实现,这次我们将重点放在 watch 的实现上。下面代码中我们添加了很多注释进行分析。这里下说下结论,在一些情况下,watch 是会重试的,并且重试之前是不会执行 list 请求的,不会执行 list 请求就不会拿到最新的 rv。那什么情况下会重试呢?一个主要的 case 就是 watch 请求五分钟会超时重连,因为 watch 请求设置了超时时间,在 watch 请求超时的时候,并不会报错,看下面代码分析。
func (r *Reflector) ListAndWatch(stopCh <-chan struct{}) error {
var resourceVersion string
// 初始的 list 请求,optoin 里只设置了 rv 选项
options := metav1.ListOptions{ResourceVersion: "0"}
// 省去不相关代码...
if err := func() error {
go func() {
pager := pager.New(pager.SimplePageFunc(func(opts metav1.ListOptions) (runtime.Object, error) {
return r.listerWatcher.List(opts)
}))
if r.WatchListPageSize != 0 {
pager.PageSize = r.WatchListPageSize
}
// 全量 list
list, err = pager.List(context.Background(), options)
}()
// 将全量 list 的 resourceVersion 修改为最新的 rv
resourceVersion = listMetaInterface.GetResourceVersion()
// 省去不相关代码...
}(); err != nil {
return err
}
// 下面是 watch 请求,放在一个无限 for 循环里
for {
// 这里的 minWatchTimeout hardcode 定义为 5 * time.Minute
timeoutSeconds := int64(minWatchTimeout.Seconds() * (rand.Float64() + 1.0))
options = metav1.ListOptions{
ResourceVersion: resourceVersion,
// 这里的时间是 [5, 10) 分钟的一个随机数
TimeoutSeconds: &timeoutSeconds,
// 开启 bookmark 机制
AllowWatchBookmarks: true,
}
// 发送 watch 请求
w, err := r.listerWatcher.Watch(options)
if err != nil {
switch err {
case io.EOF:
case io.ErrUnexpectedEOF:
klog.V(1).Infof("%s: Watch for %v closed with unexpected EOF: %v", r.name, r.expectedType, err)
default:
utilruntime.HandleError(fmt.Errorf("%s: Failed to watch %v: %v", r.name, r.expectedType, err))
}
// 如果是 ConnectRefused 错误,并不 return,使用 continue 继续下一轮循环,也就是重新发送 watch 请求
// 注意这个是一个 watch 重新发送的 case 1,即不发送 list 请求,但是发送 watch 请求
if utilnet.IsConnectionRefused(err) {
time.Sleep(time.Second)
continue
}
return nil
}
// 下面是处理 watch 请求了,我们看到 return 的情况是出现错误的情况
// 这里有个陷阱是,这个 watchHandler 可能会无疾而终,不出现错误而退出
if err := r.watchHandler(start, w, &resourceVersion, resyncerrc, stopCh); err != nil {
if err != errorStopRequested {
switch {
case apierrs.IsResourceExpired(err):
klog.V(4).Infof("%s: watch of %v ended with: %v", r.name, r.expectedType, err)
default:
klog.Warningf("%s: watch of %v ended with: %v", r.name, r.expectedType, err)
}
}
return nil
}
}
}
// 监听事件
func (r *Reflector) watchHandler(start time.Time, w watch.Interface, resourceVersion *string, errc chan error, stopCh <-chan struct{}) error {
loop:
for {
select {
case <-stopCh:
return errorStopRequested
case err := <-errc:
return err
case event, ok := <-w.ResultChan():
// 这个 case 我们需要注意一下,因为这个 ok 可能确实不 ok,在不 ok 的情况下,这个 break 直接跳出了 for 循环
// 在超时情况下,这个 ResultChan 返回给我们的,是一个已经关闭的 channel,这个时候就不 ok 了。
if !ok {
break loop
}
newResourceVersion := meta.GetResourceVersion()
switch event.Type {
// 下面是处理事件,不是我们考虑的重点,省去代码...
case watch.Added:
}
// 更新 rv
*resourceVersion = newResourceVersion
r.setLastSyncResourceVersion(newResourceVersion)
}
}
// break 跳出 for 循环后,就通过 return nil 的形式返回了。
return nil
}
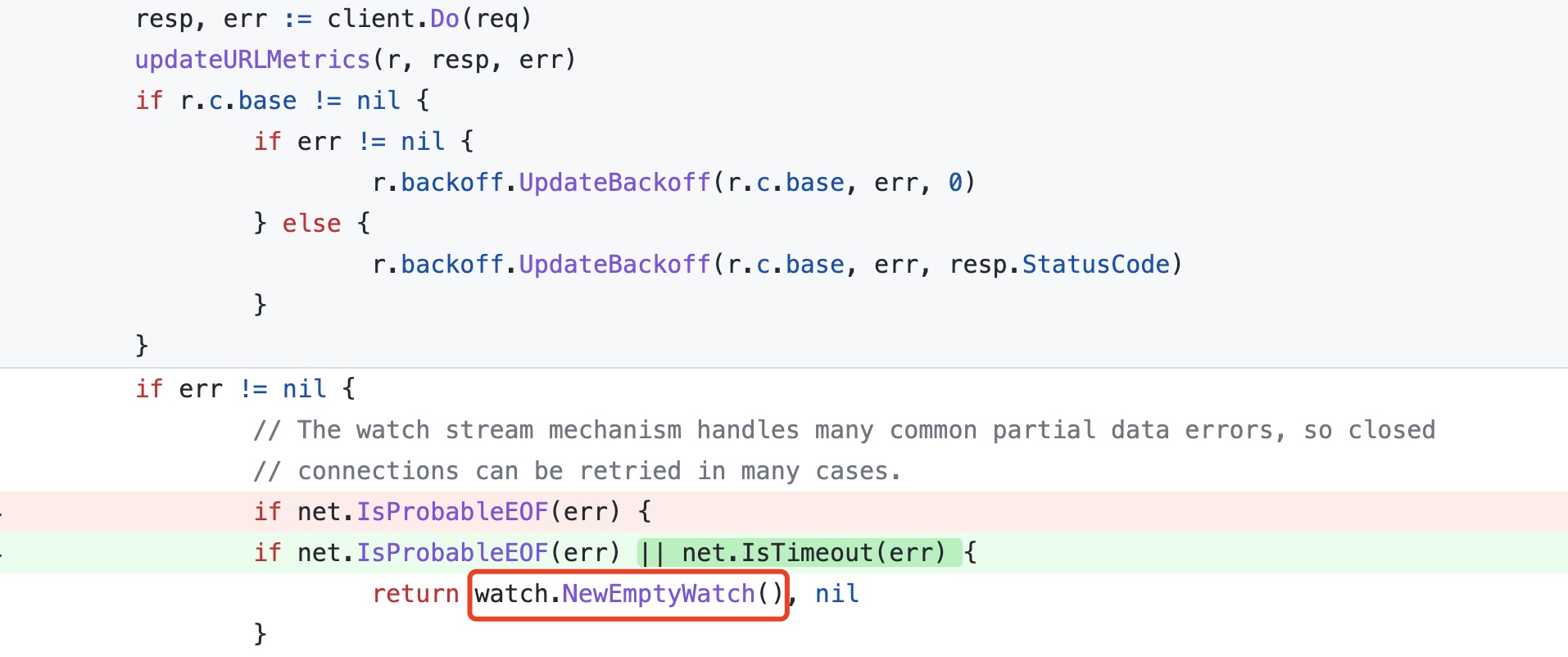
在 reflector 实现中,我们看到 watch 请求设置了超时时间,关于这个 watch 超时时间的设置可以参考 PR Fix client watch reestablishment handling of client-side timeouts,在这个 PR 中,如果遇到了 timeout error,则返回一个 watch.NewEmptyWatch(),这个 emptyWatch 的 channel 是 close 的,所以在读这个 emptywatcher 的时候,会直接返回,不会阻塞。也就是上面 watchHandler 中读 ResultChan 直接返回的情况,并且直接返回后,return 的是 nil,并没有报错,所以 watch 请求在整个 for 循环中又会重新执行一遍,并没有发生 list 请求,rv 没有更新,所以这个时候,如果 rv 太旧了,就会触发报错。
func NewEmptyWatch() Interface {
ch := make(chan Event)
close(ch)
return emptyWatch(ch)
}
下图中是 PR 对应的修改。
另外我们需要注意,我们在 listoption 中配置了 TimeoutSeconds 超时时间,这个超时时间是全局的,并且不管有没有事件都会超时。这个时间最终会配置到 Request 的 timeout 字段,并且会通过这个字段生成一个 context,请求的时候会通过 req.WithContext 生成一个新请求。下面的 timeout 字段除了我们在 options 中配置,还有一个配置入口,就是通过 kubeconfig 文件生成 restconfig 的时候,那个配置入口是全局的,一般我们不会配置。
// 位于文件:staging/src/k8s.io/client-go/rest/request.go
// Timeout makes the request use the given duration as an overall timeout for the
// request. Additionally, if set passes the value as "timeout" parameter in URL.
func (r *Request) Timeout(d time.Duration) *Request {
if r.err != nil {
return r
}
r.timeout = d
return r
}
遇到 too old rv 问题怎么办?
如果是 reflector 中报这个问题,我们是不需要处理的,因为 reflector 在遇到这个错误的时候,会重新 list 拿到最新的 rv。如果是我们自己写的 watch 请求遇到这个问题,那我们就要感知到这个错误并重新list,处理方式还是比较简单的。
通过这个问题,我们还是了解到了 K8s 一些更深入的运行原理。
综上所述,在 K8s reflector 的实现中,会存在 watch 重试的情况(重试或网络异常),当 watch 关注的资源不更新,一直收不到事件,就会出现 too old rv 的问题。