目录
指标类型及使用
参考官方文档 METRIC TYPES,官方文档同时给出了每种指标类型的代码 example。
- Gauge:表示可以任意增加或者减小的指标,比如内存使用量,气温等。
- Counter:表示一个一直增加的指标,比如总请求数等。
- Histogram:调用 Observe(float64) 对指标进行采样,同时将采集到的指标统计到预先配置的 bucket 中,在采集到的指标中,显示每个 bucket 的区间,以及每个区间中指标的个数。Histogram 可以用来采集请求时延,以及返回数据大小等。比如
prometheus_tsdb_compaction_chunk_range_bucket{le="100"} 0 prometheus_tsdb_compaction_chunk_range_bucket{le="1.6384e+06"} 260 prometheus_tsdb_compaction_chunk_range_bucket{le="2.62144e+07"} 780 prometheus_tsdb_compaction_chunk_range_bucket{le="+Inf"} 780 prometheus_tsdb_compaction_chunk_range_sum 1.1540798e+09 prometheus_tsdb_compaction_chunk_range_count 780Histogram 除了提供了每个 bucket 中的指标总数,还提供了一个 sum 值,以及一个 count 值,前者是采集到的指标的数值的所有的和,后者是采集的次数。下面的 Summary 同样提供了 sum 以及 count。
- Summary:Summary 跟 Histogram 基本一致,应用场景也基本一致。不同的是,Summary 显示的分位点的数值,Exporter 这边在采样时进行了统计(内置在业务代码中的客户端负责计算分位点),以下面三个分位点为例,
{quantile="0.5"} 0.012352463表示,50% 的 fsync 时延都在0.012352463秒以内。prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463 prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173 prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002 prometheus_tsdb_wal_fsync_duration_seconds_count 216
查询结果数据类型
根据查询数据的方式,查询结果可分为四种类型:
- instant vector:查出来的数据都是瞬时的结果(同一个时间点的数据),每个采样指标只有一个值,有很多不同的采样指标,这些采样指标的时间戳都是一样的,所以在理解 instant vertor 时,可以理解为一条竖线,竖线的每一个点表示指标名相同,但是 label 不同的不同 metrics。
- range vector:查出来的是一段时间范围内的数据,这段时间是需要通过中括号在查询语句中给出来的,比如
http_requests_total{job="prometheus"}[5m]采集最近 5 分钟内,job 标签为 prometheus 的所有指标。 - scalar:一个浮点数。
- string:一个字符串。(没有用到)
关于 prometheus 的时序数列指标以及数据类型,《understanding the Prometheus rate() function》有两张图值的看一下:
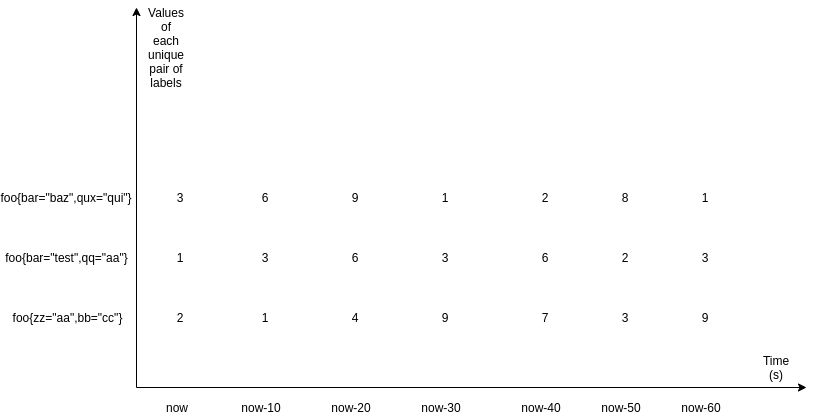 上面是三个采样指标,指标名称都一样,但是标签不一样(所以是三个不同的 metrics),也是通过三个不同的时序序列来表示的。横轴表示时间,上图显示了最近 60 秒的采样数据,每个指标都是一个序列。上面是一个 Range vector,有一个时间范围。
上面是三个采样指标,指标名称都一样,但是标签不一样(所以是三个不同的 metrics),也是通过三个不同的时序序列来表示的。横轴表示时间,上图显示了最近 60 秒的采样数据,每个指标都是一个序列。上面是一个 Range vector,有一个时间范围。
 这个是一个 instant vector,只显示了指标 foo 在某一个时刻的值,但是有三个采样,表示不同的采样指标。这两个图很有代表性。
这个是一个 instant vector,只显示了指标 foo 在某一个时刻的值,但是有三个采样,表示不同的采样指标。这两个图很有代表性。
聚合运算符
prometheus 提供了一些聚合运算符,关于聚合操作可以参考官方文档 aggregation operators,目前有以下聚合操作:
sum (calculate sum over dimensions)
min (select minimum over dimensions)
max (select maximum over dimensions)
avg (calculate the average over dimensions)
# ...其他聚合操作参考官方文档
聚合运算符只能接受 instant vector(即只能接受一条竖线或者一个点),输出也是 instant vector。这些运算符可以聚合所有的指标,或者根据 label 分组聚合,根据 label 分组聚合时,有两个关键字 by 和 without 可选。使用方式如下:
<aggr-op> [without|by (<label list>)] ([parameter,] <vector expression>)
将 by/without 放在后面也是可以的。label list 是一组标签列表,不需要加引号。by 表示按照特定的一组 label 分组(without 语义与其相反)。以 sum 为例,by 括号后面的 label 相同的 metrics 为一组,一组内的 metrics 进行累加(instant vector 累加);by 括号里的 labels 不同的 metrics 形成了新的 instant vector。
如 sum by (application, group) (http_requests_total) 是按照标签 application 以及 group 分组,相同的为一组并进行累加。
我们在监控 K8s kube-apiserver 时,需要监控请求的 qps,这个时候我们可以先用 rate 来计算每秒的 qps,然后按照资源(resource)以及方法(verb)来分组,来查看特定资源类型以及请求的 QPS。参考《A Deep Dive into Kubernetes Metrics — Part 4: The Kubernetes API Server》,查询语句为:
sum(rate(apiserver_request_count[5m])) by (resource,subresource,verb)
上面先通过 rate 对 5m 内的请求求平均值,这个平均值也就是一个 qps,rate 的结果是一个 instant vector,每个 metrics 的 label 组合都是不一样的,然后 sum 的作用就是将这个 instant vector 按照 label 求和,根据哪些 label 由 by 语句指定,所以 sum 的结果也是一个 qps,但是是根据label组合之后的 qps。
Count 函数
PromQL 的 Count 函数包括 rate/irate/increase/reset,它们都接受一个 range vector,并返回一个 instant vector。
rate 与 irate
rate(v range-vector) 只作用于 range vector,并且只适用于 counter 指标类型,其输出为 instant vector,用来计算每秒增长率,也就是每秒增长的个数,如 rate(http_requests_total{job="api-server"}[5m])
计算 5 分钟内,每秒的增长数,计算方式就是这五分钟内增长的总数(当前总数 - 5分钟之前的总数),除以 5 分钟内的所有秒数。rate 能自动检测到指标重置(组件重启),因为是counter类型,指标采集的数据是只增不减的,如果遇到下降的指标,表示组件重启了,rate 在计算的时候,会将下降的指标累加之前的最大值,参考《understanding the Prometheus rate() function》。
相对于 rate 函数来说,irate 函数是 prometheus 针对长尾效应专门提供的灵敏性更高的函数,其反应出的是瞬时的增长率。在计算时,只会考虑最近的两个采样点,并除以这里两个点的 interval。假设有下面 6 个采样点,每个采样点的间隔是 1 分钟:
0
60
120
600
720
780
那么 rate 的计算方式为 (780-0)/5/60 = 2.6/sec irate 的计算方式为 (780-720)/1/60 = 1/sec。在订制告警规则时,建议使用 rate,而不是 irate,前者更稳定一些。
当将 rate/irate 函数与聚合运算符如 sum 一起使用时,必须先执行 rate 函数,再执行聚合操作,否则当采样目标重启时,rate 函数无法检测到计数器是否被重置。
increase
increase 计算一个区间内的增长量(区别于 rate 的增长率)。
本地 metrics 数据缓存
prometheus exporter 采集的指标都是缓存在程序本地的,然后等着 prometheus server 定期来拉(pull 模型),那指标在程序本地都是怎么存储的呢?其实只要记住一条就好理解了:一条 metrics 是由 metrics name 以及一组 label 唯一确认的。不同的指标在本地都有一条记录,以 gauge 类型的指标为例,相同的指标(label 也相同)采集到了值会进行覆盖,如果 label 不同,则会记另一条 metrics 记录。然后这些 metrics 就一直缓存在本地,直到重启。
在 kubelet 中,有些 gauge 类型的指标,只会在 kubelet 启动时采集一次,然后就被缓存在本地。比如 NodeName 指标。
// NodeName is a Gauge that tracks the ode's name. The count is always 1.
NodeName = metrics.NewGaugeVec(
&metrics.GaugeOpts{
Subsystem: KubeletSubsystem,
Name: NodeNameKey,
Help: "The node's name. The count is always 1.",
StabilityLevel: metrics.ALPHA,
},
[]string{NodeLabelKey},
)
在本地缓存指标时,prometheus exporter 主要依靠的是 MetricVec 以及 metricMap 数据结构,采集指标时,会对所有 label 计算出一个 hash,将这个 hash 作为 key 存到 map 中。
type MetricVec struct {
*metricMap
curry []curriedLabelValue
// hashAdd and hashAddByte can be replaced for testing collision handling.
hashAdd func(h uint64, s string) uint64
hashAddByte func(h uint64, b byte) uint64
}
type metricMap struct {
mtx sync.RWMutex // Protects metrics.
metrics map[uint64][]metricWithLabelValues
desc *Desc
newMetric func(labelValues ...string) Metric
}
参考《Prometheus源码分析:基于Go Client自定义的Exporter,是如何在Local存储Metrics的》