Kubelet有个Topology Manager可以对Guaranteed的Pod进行绑核,绑核有两个条件:
- Pod需要为
GuaranteedQOS,并且cpu数值必须为整数核数。 - Kubelet的参数
cpu-manager-policy必须设置为static,这个可以参考Control CPU Management Policies on the Node
另外如果pod只设置了limit没有设置request,那么request会被设置成跟limit一样的值。对于不绑NUMA的容器,限制CPU的策略为使用cgroup cpu share来限制使用百分比,使用cgroup cpu quota来限制上限,绑核就是设置合适的cgroup cpuset,使分配的cpuset都在一个NUMA上。
目前Topology Manager的主要功能是为Pod中的容器选择cpu,并尽量保证选择的cpu不跨NUMA。如果了NUMA,则CPU访问跨NUMA的内存时,代价较大,也就是Non-Uniform Memory Access(非一致性内存访问)的含义。绑NUMA对CPU敏感的任务比较有用,比如cpu切换代价比较大的,对L3cache比较敏感的,跨NUMA访问内存比较敏感的等。
这里cpuset numa相关稍微介绍了一点NUMA的内容,官方文档里也有一张图:
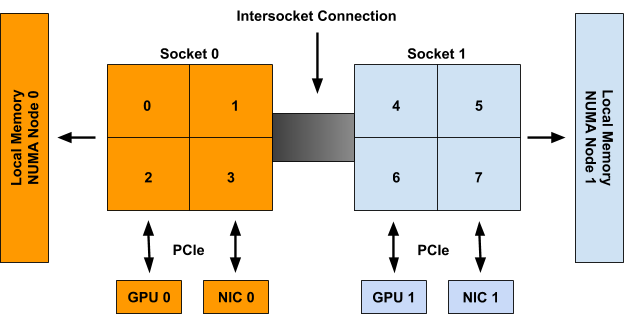
从上图可以看出一个支持NUMA的CPU的结构:一个NUMA系统被分为多个NUMA节点,每个NUMA节点有多个Socket(虽然上图中只有一个),每个Socket上有一个NUMA Memory节点,多个cpu,也可能包含独立的GPU卡,NIC卡等。TopologyManager的作用就是为容器选择合适的逻辑cpu。
Kubelet提供了配置Topology Manager策略的参数,目前这些参数是针对所有Pod都起作用的(社区有只对部分Pod作用的想法,但是没有好的方案),配置的参数为:--topology-manager-policy,供选择的参数为:
- none: 跟没有TopologyManager一个效果
- best-effort:尽量不跨NUMA,但是垮NUMA了也能正常启动
- restricted: 尽量不跨NUMA,但是如果申请的资源只能由多个NUMA提供,那么没办法了,也是允许的,比如申请了两个GPU卡,但是一个NUMA只有一个GPU卡。
- single-numa-node:不能跨NUMA。否则就reject。
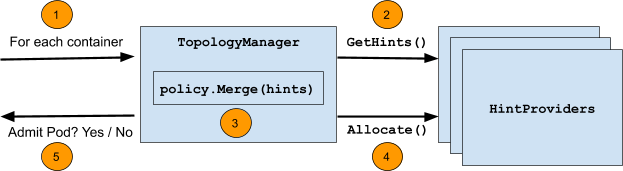
下面这个图大致说明了topology-manager的工作原理,对于Pod中的每个容器(container,而不是pod),通过HintProviders获取分配硬件的建议(Hint),可以是cpu,也可以是gpu-vendor.com/gpu或nic-vendor.com/nic,每个Providers可以有多个建议。topology-manager会将所有的建议汇总,找一个最终方案,并通过HintProvider来进行分配。上述步骤如果出错或者不可分配不满足设置的策略,则对Pod进行Reject。如果Pod被Reject,其状态为Terminated,需要一个控制器来重新拉起一个新的pod,比如deployment控制器等。
深入理解 Kubernetes CPU Mangager这篇文章介绍了Checkpoint文件(存放当前cpu分配状态的文件)被删除或者损坏时的处理情况,有两种方式:1)删除文件,重启kubelet,CPU manager的Reconcile会重新生成文件,重新分配cpu,可能会造成应用的短暂抖动。2)将这个节点下线。
不足
这里只关心调度器的行为,如果调度器将pod调度到了节点上,但是却被topology-manager拒绝了,也挺尴尬的,一般的想法也就是将CPU的信息传递给scheduler,让scheduler在做决策的时候,能够考虑绑核的情况,传递信息的方式,一种是直接放到node annotation里,另一种方式考虑scheduler是否可以直接调用TopologyManager的相关接口。