目录
在并发编程中,为防止多个 goroutine 同时修改一个对象,我们一般是事先设置一把锁 sync.Mutex,要想修改对象,需要提前获取这把锁,拿不到锁就需要阻塞,直到其他 goroutine 释放锁。相对于 sync.Mutex(排它锁、不可重入锁),CAS(compare-and-swap)操作是一种乐观锁机制,goroutine 在修改对象时,不需要获得锁,只要满足了一定条件就能修改。在 Wikipedir: Compare-and-swap中,CAS 操作的伪代码为:
function cas(p: pointer to int, old: int, new: int) is
if *p != old
return false
*p <- new
return true
整个过程描述为:查看 p 指向的内存的内容是否是 old,如果是则修改为新值 new,否则返回 false,表示修改未成功。p 指向的内容不是 old,说明已经有其他线程修改了 p 的值,因此需要重新调用 CAS 操作尝试修改,在计算机中,整个 CAS 操作是原子的,即对比和设置过程是不可分割的(不能被中断),并且 cpu 在对 p 所指向的内存执行 cas 操作时,该内存就处于锁定状态,其他 cpu 处理不了这块内存。这个通过需要通过计算机 cas 指令来支持。
Golang 中的 CAS 操作
Golang 在 sync/atomic 包中定义了一些原子操作,比较常见的有 atomic.AddInt64 等,表示对一个 int64 类型加上一个 delta,使用方式如下,如果不使用 atomic.AddInt64,而是直接使用 intVal += 10,很大概率得到的和是达不到 1000 的,比如 980 等。
var intVal int64 = 0
wg := &sync.WaitGroup{}
wg.Add(1000)
for i:=0; i<1000;i++ {
go func() {
// intVal += 10 // 980
atomic.AddInt64(&intVal, 1)
wg.Done()
}()
}
wg.Wait()
fmt.Println(intVal) // 正常输出 1000
同时,在 sync/atomic 中还定义了 cas 操作,比如 CompareAndSwapPointer 表示原子的配置指针的值,成功返回 true,失败返回 false。
func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool)
func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool)
实现无锁队列
文章《使用 Go 实现 lock-free 的队列》中实现了一个无锁队列,其代码仓库为 https://github.com/smallnest/queue,该实现是基于论文《Simple, Fast, and Practical Non-Blocking and Blocking Concurrent Queue Algorithms》 中的算法实现的,在该仓库中还有其他两种队列的实现,目前我们只关注无锁队列。
我们首先回顾一下队列这个数据结构,包含两个操作:入队(Enqueue)和出队(Dequeue),以 FIFO 队列为例,从队尾入队,从对头出队。在文章《使用 Go 实现 lock-free 的队列》中提到的无锁队列是通过链表实现的,并且链表带有头尾两个指针,便于出队和入队。另外在 https://github.com/golang-design/lockfree/blob/master/queue.go项目中(欧长坤大佬写的),也有一个无锁队列的实现,基本一致,不再赘述。
相关数据结构
通过链表来实现无锁队列,链表带一个头结点,链表有一个头指针和尾指针,分别指向头结点和最后一个节点。
type LKQueue struct { // 链表定义
head unsafe.Pointer
tail unsafe.Pointer
}
type node struct { // 链表中的节点定义
value interface{}
next unsafe.Pointer
}
func NewLKQueue() *LKQueue { // 初始状态下, head == tail,都指向头结点
n := unsafe.Pointer(&node{})
return &LKQueue{head: n, tail: n}
}
// 原子的读取(Load)指针的值
func atomic_LoadPointer(p *unsafe.Pointer) (n *node) {
return (*node)(atomic.LoadPointer(p))
}
// 通过 cas 操作来设置指针的值
func atomic_CompareAndSwapPointer(p *unsafe.Pointer, old, new *node) (ok bool) {
return atomic.CompareAndSwapPointer(p, unsafe.Pointer(old), unsafe.Pointer(new))
}
在链表中,指针的类型都使用了 unsafe.Pointer 类型,这样可以直接使用 sync/atomic 包中的func LoadPointer(addr *unsafe.Pointer) (val unsafe.Pointer) 方法来原子的读取指针的值,LoadPointer 方法中,第一个参数是一个指针,指向要配置的空间的地址,因为我们要配置的是 unsafe.Pointer,所以这里是指向 unsafe.Pointer 的指针。
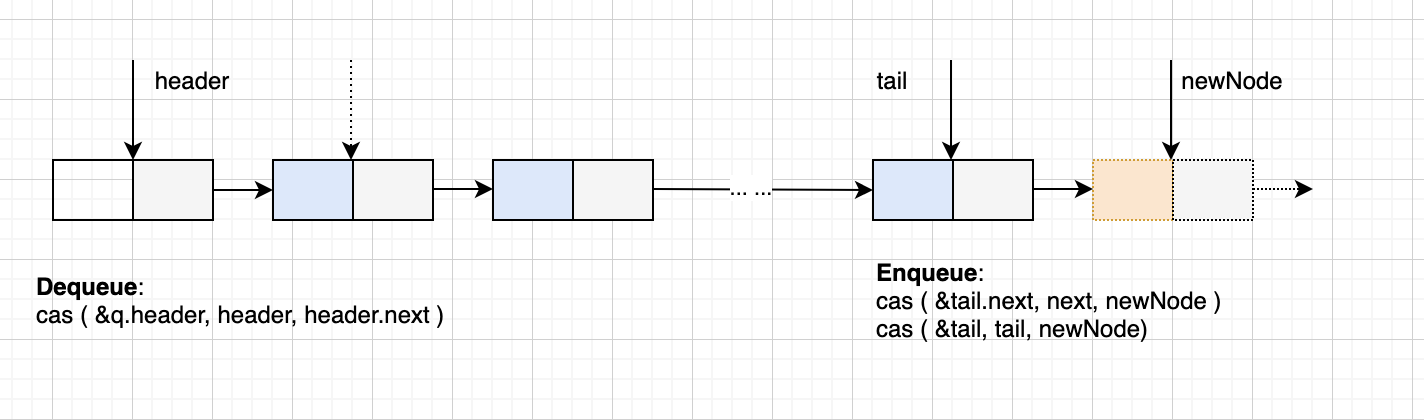
链表结构示意图如下,图中标注了几个重要的 cas 操作,即在入队和出队需要进行的操作,不过还有一些 corner case 没有标注,但是很重要。
算法实现
具体入队和出队的操作代码如下,代码中加了一些注释,还有一些需要注意的点,具体为:
- 入队:入队前要先拿到当前的 tail 以及 tail.next,拿了之后要 double check tail 是不是在刚刚拿的时候被修改了。入队时要检查 tail.next 是不是空,因为可能上次入队的时候,tail 的后移操作没有成功。所以入队时首先进行的是补偿机制,如果上次 tail 没有后移,先后移后再入队。另外入队后的 tail 后移操作是不保证成功的。
- 出队:出队时,直接删除头结点,并将头结点的 next 作为头结点,这样是没问题的,因为我们不会访问头结点中的元素,只使用其中的 next 指针。出队前要拿到三个值:当前 head,tail,head.next,拿到之后,也要 double check 一下拿的过程中, head 有没有被修改。同时也要处理队列为空的情况。
func (q *LKQueue) Enqueue(v interface{}) {
newNode := &node{value: v}
for {
// 取得当前的尾指针以及尾指针的 next
tail := atomic_LoadPointer(&q.tail)
next := atomic_LoadPointer(&tail.next)
if tail == atomic_LoadPointer(&q.tail) { // are tail and next consistent?
if next == nil {
if atomic_CompareAndSwapPointer(&tail.next, next, newNode) {
// 入队成功,尝试后移 tail,这个是不保证成功的
// 后移不成功时,下次入队会重新后移,也就是 for 循环里的最后一个 else 语句
atomic_CompareAndSwapPointer(&q.tail, tail, newNode)
return
}
} else { // tail 指向的不是最后一个节点,说明有元素入队了,并且入队的时候,更新tail 没有成功
// 执行 tail 后移操作
atomic_CompareAndSwapPointer(&q.tail, tail, next)
}
} else {
// 当 if 语句不成立的时候,说明刚刚取到的 tail 已经不是 tail 了,我们必须要找到
// 真正的 tail 才能继续执行入队操作
}
}
}
func (q *LKQueue) Dequeue() interface{} {
for {
head := atomic_LoadPointer(&q.head)
tail := atomic_LoadPointer(&q.tail)
next := atomic_LoadPointer(&head.next)
if head == atomic_LoadPointer(&q.head) { // are head, tail, and next consistent?
if head == tail { // is queue empty or tail falling behind?
if next == nil { // is queue empty?
return nil
}
// head 等于 tail,并且 tail 的 next 不为 nil,tail 需要后移
atomic_CompareAndSwapPointer(&q.tail, tail, next)
} else {
// head 不等于 tail,这个是正常的情况
// read value before CAS otherwise another dequeue might free the next node
v := next.value
if atomic_CompareAndSwapPointer(&q.head, head, next) {
return v // Dequeue is done. return
}
}
} else {
// 这里说明刚刚拿到的 header 已经不是 header 了,需要重新拿 header
}
}
}
支撑无锁队列实现的理论基础是论文《Simple, Fast, and Practical Non-Blocking and Blocking Concurrent Queue Algorithms》,在看算法的时候,有一些case 不是很清晰,一直在想,难道我要去读一下这个论文吗?一个小小的队列也是不简单的,对数据结构以及算法的设计要有敬畏之心,那天有时间了,读读这个论文也行。
参考
《无锁队列的实现》
《Simple, Fast, and Practical Non-Blocking and Blocking Concurrent Queue Algorithms》