目录
之前在《关于k8s informer的基本概念与原理》中介绍过informer的一些东西,但是没怎么讲清楚,这里再梳理一下知识点。还是以项目 sig-storage-lib-external-provisioner 为例,这些项目逻辑比较简单,相对容易分析。
主体流程
这里主要是说从声明一个 informer,到启动这个 informer 的过程,这个应该都比较熟悉了。这里再复习一下相关的数据结构,以及它们之间的相互关系。
声明
provisioner 项目主要对 pvc 以及 pv 感兴趣,所以声明了如下 pvc 以及 pv Informer,另外这里把存放 pvc 以及 pv 的本地 cache 也暴露出来了。
claimInformer cache.SharedIndexInformer
claimsIndexer cache.Indexer
volumeInformer cache.SharedInformer
volumes cache.Store
我们先看下SharedIndexInformer以及SharedInformer的定义,前者嵌入了后者,并添加了AddIndexers以及GetIndexer方法,需要注意的是,添加 indexer 需要在 informer 启动之前添加,否则会返回错误。SharedInformer的接口定义主要包括添加 EventHandler,启动 informer 等。
type SharedIndexInformer interface {
SharedInformer
// AddIndexers add indexers to the informer before it starts.
AddIndexers(indexers Indexers) error
GetIndexer() Indexer
}
type SharedInformer interface {
AddEventHandler(handler ResourceEventHandler)
// 带 resync 的 EventHandler
AddEventHandlerWithResyncPeriod(handler ResourceEventHandler, resyncPeriod time.Duration)
// GetStore returns the informer's local cache as a Store.
GetStore() Store
// 已废弃
GetController() Controller
Run(stopCh <-chan struct{})
// 至少从Etcd进行过一次FULL LIST之后,HasSynced返回true
HasSynced() bool
// LastSyncResourceVersion is the resource version observed when last synced with the underlying
// store. The value returned is not synchronized with access to the underlying store and is not
// thread-safe.
LastSyncResourceVersion() string
SetWatchErrorHandler(handler WatchErrorHandler) error
}
Store接口定义了对本地 cache 的 CRUD 操作。除了通过GetStore接口直接拿到本地cache的操作接口,我们还可以定义一个 Lister 来对本地 cache 进行读操作,Lister可以通过labels.Selector进行选取,也可以通过name获取特定的资源,通过 lister 获取的资源,必须视为 read-only 的,否则会修改本地 cache,导致跟etcd 数据不一致,另外由于本地 cache 会自动同步,做的修改可能会被同步操作覆盖掉。
一般来讲,我们不需要通过Store接口来对资源进行 get/delete 操作,通过 Lister 接口足够了。Store接口也不支持通过labels.Selector来进行选择。K8s的informer 机制会自动更新本地 cache,(在某些情况下需要手动添加资源到本地cache,这种操作主要是省去 informer 自动同步的时延,手动添加到本地 cache 之后,后续的操作都直接能看到,这里先不考虑这些 case)。
//Informer = informer.Core().V1().PersistentVolumeClaims().Informer()
pvLister := informer.Core().V1().PersistentVolumeClaims().Lister()
初始化及启动
初始化的过程是,通过SharedInformerFactory生成特定资源的 informer,然后调用这个 informer 的 Run 方法,或者直接调用SharedInformerFactory的Start(stopCh <-chan struct{})方法,但是这里的 informer 可能由其他的 informerFactory 生成(在用户定制化 informer 的情况下),所以这里调用了特定资源的Run方法。
informer := informers.NewSharedInformerFactory(client, controller.resyncPeriod)
controller.claimInformer = informer.Core().V1().PersistentVolumeClaims().Informer()
claimHandler := cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) { controller.enqueueClaim(obj) },
UpdateFunc: func(oldObj, newObj interface{}) { controller.enqueueClaim(newObj) },
DeleteFunc: func(obj interface{}) {},
}
controller.claimInformer.AddEventHandler(claimHandler)
if !ctrl.customClaimInformer {
go ctrl.claimInformer.Run(ctx.Done())
}
创建 InformerFactory 时,除了使用使用默认值时,调用NewSharedInformerFactory方法(该方法需要指定一个参数defaultResync),还有下面两个方法可用,可以对 Informer 进行定制化,默认情况下tweakListOptions参数为 nil。
func NewFilteredSharedInformerFactory(client kubernetes.Interface, defaultResync time.Duration, namespace string, tweakListOptions internalinterfaces.TweakListOptionsFunc) SharedInformerFactory {
return NewSharedInformerFactoryWithOptions(client, defaultResync, WithNamespace(namespace), WithTweakListOptions(tweakListOptions))
}
// NewSharedInformerFactoryWithOptions constructs a new instance of a SharedInformerFactory with additional options.
func NewSharedInformerFactoryWithOptions(client kubernetes.Interface, defaultResync time.Duration, options ...SharedInformerOption) SharedInformerFactory {
factory := &sharedInformerFactory{
client: client,
namespace: v1.NamespaceAll,
defaultResync: defaultResync,
informers: make(map[reflect.Type]cache.SharedIndexInformer),
startedInformers: make(map[reflect.Type]bool),
customResync: make(map[reflect.Type]time.Duration),
}
// Apply all options
for _, opt := range options {
factory = opt(factory)
}
return factory
}
等待同步及启动 worker goroutine
WaitForCacheSync是每个 informerFactory 以及 informer 启动后都要做的事,根据注释,其含义是等待本地 cache 至少进行一次FULL LIST操作。
if !cache.WaitForCacheSync(ctx.Done(), ctrl.claimInformer.HasSynced, ctrl.volumeInformer.HasSynced, ctrl.classInformer.HasSynced) {
return
}
for i := 0; i < ctrl.threadiness; i++ {
go wait.Until(func() { ctrl.runClaimWorker(ctx) }, time.Second, ctx.Done())
}
WaitForCacheSync底层的实现查看 Reflector 的pupulated以及initialPopulationCount字段,下面有解释,概括来讲,就是将 Reflector 的 List 的操作结果都放到DeltaFifo队列里了,并且又被 DeltaFIFO 的 Pop 方法消费了(每调用一次 pop,initialPopulationCount值就减1),Pop 消费的方式之一就是添加到本地 cache 中。具体实现如下:
func (f *DeltaFIFO) HasSynced() bool {
f.lock.Lock()
defer f.lock.Unlock()
return f.populated && f.initialPopulationCount == 0
}
另一个问题是,为什么启动 Controller 之前要先等待缓存同步,一个比较容易想到的原因是,本地 cache 作为 etcd 的缓存,应该跟 etcd 保持一致,如果没有等到 cache同步,List 的结果或者 Get 结果有可能现象不一致,比如 etcd 有,但是本地没有。这个可以参考下A deep dive into Kubernetes controllers,这个文章我还没看,有可能有出入。
Reflector 工作原理
在上一小节中,启动informer用的是claimInformer.Run方法,这个方法创建一个 informer 机制中的controller,并在运行此 controller 的时候创建一个reflector并运行。Run方法如下:
func (s *sharedIndexInformer) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
// 创建一个Delta队列,KnownObjects 是本地缓存的 ListKeys 以及 GetByKey 方法
fifo := NewDeltaFIFOWithOptions(DeltaFIFOOptions{
KnownObjects: s.indexer,
EmitDeltaTypeReplaced: true,
})
cfg := &Config{
Queue: fifo,
ListerWatcher: s.listerWatcher,
ObjectType: s.objectType,
FullResyncPeriod: s.resyncCheckPeriod,
RetryOnError: false,
ShouldResync: s.processor.shouldResync,
Process: s.HandleDeltas,
WatchErrorHandler: s.watchErrorHandler,
}
func() {
s.startedLock.Lock()
defer s.startedLock.Unlock()
// 创建controller
s.controller = New(cfg)
s.controller.(*controller).clock = s.clock
s.started = true
}()
// Separate stop channel because Processor should be stopped strictly after controller
processorStopCh := make(chan struct{})
var wg wait.Group
defer wg.Wait() // Wait for Processor to stop
defer close(processorStopCh) // Tell Processor to stop
wg.StartWithChannel(processorStopCh, s.cacheMutationDetector.Run)
wg.StartWithChannel(processorStopCh, s.processor.run)
defer func() {
s.startedLock.Lock()
defer s.startedLock.Unlock()
s.stopped = true // Don't want any new listeners
}()
s.controller.Run(stopCh)
}
DeltaFIFO 队列
DeltaFIFO首先是一个 FIFO 队列,其主要字段是 items 和 queue,其定义如下:
items: 是一个 map 结构,其 key 为特定 object 的 Key,value 为这个 object 的事件列表,特定 object 的事件列表Deltas是一个 Slice,是有序的。但是 items 因为是一个 map 结构,所以是无序的。items 的定义可以参考default/pod1: update/update/delete,表示 default namespace 的 pod1 有三个事件,分别为 update、update、delete。queue: 是一个 slice 结构,queue 存在的意义主要是 items 是无序的,为了维护不同 object 事件发生的先后循序,使用了一个 slice 结构。另外需要注意的是,queue字段中不包含重复的元素,在 append 这个Slice的时候,先检查items是否有该元素(遍历 queue 检查),如果没有再进行 append,也就是下面注释中说的,items与queue是1:1映射的,他们的元素个数总是相等的。
关于 populated 字段,只要调用过DeltaFIFO的Delete或者Add或者Update等方法,这个字段就是被设置为 true。Reflactor 的 WatchHander 是 DeltaFIFO 的生产者,会调用上面几个 CRUD 方法往 DeltaFIFO 里填数据。
initialPopulationCount字段是第一次调用Replace时,往Delta里填充的资源个数。每次调用DeltaFIFO的Pop方法消费资源时,这个数值就会减一。
type DeltaFIFO struct {
// `items` maps keys to Deltas.
// `queue` maintains FIFO order of keys for consumption in Pop().
// We maintain the property that keys in the `items` and `queue` are
// strictly 1:1 mapping, and that all Deltas in `items` should have
// at least one Delta.
items map[string]Deltas
queue []string
// populated is true if the first batch of items inserted by Replace() has been populated
// or Delete/Add/Update/AddIfNotPresent was called first.
populated bool
// initialPopulationCount is the number of items inserted by the first call of Replace()
initialPopulationCount int
// knownObjects list keys that are "known" --- affecting Delete(),
// Replace(), and Resync()
knownObjects KeyListerGetter
// 省略部分字段...
}
// 一个 Delta 表示一个事件
type Delta struct {
Type DeltaType
Object interface{}
}
// Deltas 是某个特定 object 的时间列表,这个也是有序的,最老的的事件在 index 0 的位置
type Deltas []Delta
controller
controller 不介绍了,比较容易理解,就是启动 reflector,并消费 DeltaFIFO 的资源,一方面触发 EventHandler,另一方面放到本地cache中。
这里可以说一下Pop消费Delta的方式,因为DeltaFIFO中一个资源可以有多个事件,这个事件列表放在items map[string]Deltas中,每次调用Pop弹出元素的时候,每次弹出的都是一个事件列表,然后在(s *sharedIndexInformer) HandleDeltas(obj interface{}) error方法中,对每个事件都进行一次分发。下面是 HandleDeltas代码,可以看出其有两个任务:1)更新或者删除本地 cache,2)分发事件。
func (s *sharedIndexInformer) HandleDeltas(obj interface{}) error {
s.blockDeltas.Lock()
defer s.blockDeltas.Unlock()
// from oldest to newest
for _, d := range obj.(Deltas) {
switch d.Type {
case Sync, Added, Updated:
isSync := d.Type == Sync
s.cacheMutationDetector.AddObject(d.Object)
if old, exists, err := s.indexer.Get(d.Object); err == nil && exists {
if err := s.indexer.Update(d.Object); err != nil {
return err
}
// sync 会被当成 update 事件
s.processor.distribute(updateNotification{oldObj: old, newObj: d.Object}, isSync)
} else {
if err := s.indexer.Add(d.Object); err != nil {
return err
}
// 如果本地 cache 没有,那就是 add 事件
s.processor.distribute(addNotification{newObj: d.Object}, isSync)
}
case Deleted:
if err := s.indexer.Delete(d.Object); err != nil {
return err
}
s.processor.distribute(deleteNotification{oldObj: d.Object}, false)
}
}
return nil
}
reflector 运行框架
在看reflector工作原理之前,先看一下reflector的一些参数配置。其创建代码在controller的Run方法中,
func (c *controller) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
go func() {
<-stopCh
c.config.Queue.Close()
}()
r := NewReflector(
c.config.ListerWatcher,
c.config.ObjectType,
// reflector 的 store 是 DeltaFIFO
c.config.Queue,
c.config.FullResyncPeriod,
)
r.ShouldResync = c.config.ShouldResync
r.clock = c.clock
if c.config.WatchErrorHandler != nil {
r.watchErrorHandler = c.config.WatchErrorHandler
}
c.reflectorMutex.Lock()
c.reflector = r
c.reflectorMutex.Unlock()
var wg wait.Group
wg.StartWithChannel(stopCh, r.Run)
wait.Until(c.processLoop, time.Second, stopCh)
wg.Wait()
}
关注下面几个字段:
ListerWatcher
我们在启动 PVC Informer 的时候,并没有指定 ListerWatcher,那我们看一下默认值是怎么构建的。我们创建 informer 时,使用的方法为:claimInformer = informer.Core().V1().PersistentVolumeClaims().Informer()
其最终调用的方法为NewFilteredPersistentVolumeClaimInformer,代码路径为:client-go/informers/core/v1/persistentvolumeclaim.go,其中tweakListOptions在创建factory时没有指定,默认为nil。
func NewFilteredPersistentVolumeClaimInformer(client kubernetes.Interface, namespace string, resyncPeriod time.Duration, indexers cache.Indexers, tweakListOptions internalinterfaces.TweakListOptionsFunc) cache.SharedIndexInformer {
return cache.NewSharedIndexInformer(
&cache.ListWatch{
ListFunc: func(options metav1.ListOptions) (runtime.Object, error) {
if tweakListOptions != nil {
tweakListOptions(&options)
}
return client.CoreV1().PersistentVolumeClaims(namespace).List(context.TODO(), options)
},
WatchFunc: func(options metav1.ListOptions) (watch.Interface, error) {
if tweakListOptions != nil {
tweakListOptions(&options)
}
return client.CoreV1().PersistentVolumeClaims(namespace).Watch(context.TODO(), options)
},
},
&corev1.PersistentVolumeClaim{},
resyncPeriod,
indexers,
)
}
上面的NewSharedIndexInformer最终返回一个sharedIndexInformer实例,并将listerWatcher以及下面的resyncPeriod赋值给resyncCheckPeriod等。
resyncPeriod
这个参数还是得从 Factory 的创建说起,我们在创建时指定了一个参数defaultResync time.Duration,这个参数最终被赋值给了sharedInformerFactory的defaultResync字段。
informer := informers.NewSharedInformerFactory(client, controller.resyncPeriod)
然后当我们使用 sharedInformerFactory 的方法 InformerFor 为特定资源创建Informer的时候,先检查有没有为该种资源定制化同步时间,没有定制化,就使用factory的defaultResync方法,定制化是使用装饰器方法,如下:
func WithCustomResyncConfig(resyncConfig map[v1.Object]time.Duration) SharedInformerOption {
return func(factory *sharedInformerFactory) *sharedInformerFactory {
for k, v := range resyncConfig {
factory.customResync[reflect.TypeOf(k)] = v
}
return factory
}
}
此方法跟WithTweakListOptions方法使用方式一致。上面提到了在创建sharedInformerFactory时,将resyncPeriod传递给了resyncCheckPeriod,这个参数在创建配置controller以及Reflactor的config时,再次被赋值给了Config的FullResyncPeriod,这个参数被传递了多次,还每次都重新起个名字,很绕。
cfg := &Config{
Queue: fifo,
ListerWatcher: s.listerWatcher,
ObjectType: s.objectType,
FullResyncPeriod: s.resyncCheckPeriod,
RetryOnError: false,
ShouldResync: s.processor.shouldResync,
Process: s.HandleDeltas,
WatchErrorHandler: s.watchErrorHandler,
}
这个 resync 的作用通过 knownobjects 把本地缓存的所有数据都拿出来,并触发一个 Sync 事件,这个 Sync 事件最终反映到我们的事件处理器中,是一个 update 事件,因为 Sync 是定时触发的,并不是事件驱动,所以很有可能我们收到这个 update 事件之后,什么都不需要做,在 reconcile 逻辑中,current 跟 expect 是匹配的。下面是 Sync 的定义,通过定义我们也可以看到 Sync 触发的两种情况:
- 调用全量 list 之后,因为第一次全量 list 之后要调用 replace 方法,而 replace 方法中,对所有 list 到的所有最新资源,都触发一个 Sync 事件。
- 定期的 reync。这个就是把 knownobjects 全部拿出来,触发一个 sync 事件。
const (
Added DeltaType = "Added"
Updated DeltaType = "Updated"
Deleted DeltaType = "Deleted"
Sync DeltaType = "Sync"
)
store
这里指 reflector 中的 store,这个 store 是 DeltaFIFO。reflector将事件同步到DeltaFIFO中,再通过Pop方法进行消费。
然后就是Reflecor的主要方法ListAndWatch,这个方法是通过wait.Until来运行的,(此处不通版本的 K8s 运行 reflector 的方式不同,也有通过 wait.BackoffUntil 方法来运行的,思路差不多),其中 r.period 默认是 1s,下面运行方式简单总结就是:运行 ListAndWatch 方法,如果这个方法因为某种错误返回了,隔1s重新运行,直到 stopCh 关闭。
func (r *Reflector) Run(stopCh <-chan struct{}) {
wait.Until(func() {
if err := r.ListAndWatch(stopCh); err != nil {
utilruntime.HandleError(err)
}
}, r.period, stopCh)
}
ListAndWatch首先从特定的ResourceVersion开始List,List之后,拿到最新的ResourceVersion然后开始开始watch。下面是 ListAndWatch 的整体框架。整体思路就是: 全量 list 一遍,然后基于 list 返回的 resourceVersion 开始 watch,在 watchHandler 中进行相应的事件生产(放到 DeltaFIFO 的 item 队列中),同时事件生产的时候,也要更新最新的 resourceVersion。
func (r *Reflector) ListAndWatch(stopCh <-chan struct{}) error {
klog.V(3).Infof("Listing and watching %v from %s", r.expectedTypeName, r.name)
var resourceVersion string
// relistResourceVersion决定开始list的版本号,不低于已经存在cache中的版本号
// 对于错误码410 Gone的情况(对应版本的数据etcd不存在了),这个方法返回"",表示从最新的版本号开始list
options := metav1.ListOptions{ResourceVersion: r.relistResourceVersion()}
// 这个匿名函数执行List操作
if err := func() error {
initTrace := trace.New("Reflector ListAndWatch", trace.Field{"name", r.name})
defer initTrace.LogIfLong(10 * time.Second)
// 这个list变量就是List的结果,是一个ListItem类型,需要转换为对应资源的Slice列表
var list runtime.Object
var paginatedResult bool
var err error
listCh := make(chan struct{}, 1)
panicCh := make(chan interface{}, 1)
go func() {
defer func() {
if r := recover(); r != nil {
panicCh <- r
}
}()
// 尝试使用分块传输,如果ListWatch不支持,则一次返回所有结果
pager := pager.New(pager.SimplePageFunc(func(opts metav1.ListOptions) (runtime.Object, error) {
// 使用定制化的listwatcher进行List,可以只list etcd的部分资源
return r.listerWatcher.List(opts)
}))
switch {
case r.WatchListPageSize != 0:
pager.PageSize = r.WatchListPageSize
case r.paginatedResult:
case options.ResourceVersion != "" && options.ResourceVersion != "0":
pager.PageSize = 0
}
list, paginatedResult, err = pager.List(context.Background(), options)
if isExpiredError(err) || isTooLargeResourceVersionError(err) {
r.setIsLastSyncResourceVersionUnavailable(true)
list, paginatedResult, err = pager.List(context.Background(), metav1.ListOptions{ResourceVersion: r.relistResourceVersion()})
}
close(listCh)
}()
select {
case <-stopCh:
return nil
case r := <-panicCh:
panic(r)
case <-listCh:
}
if err != nil {
return fmt.Errorf("failed to list %v: %v", r.expectedTypeName, err)
}
if options.ResourceVersion == "0" && paginatedResult {
r.paginatedResult = true
}
r.setIsLastSyncResourceVersionUnavailable(false) // list was successful
initTrace.Step("Objects listed")
listMetaInterface, err := meta.ListAccessor(list)
if err != nil {
return fmt.Errorf("unable to understand list result %#v: %v", list, err)
}
resourceVersion = listMetaInterface.GetResourceVersion()
initTrace.Step("Resource version extracted")
items, err := meta.ExtractList(list)
if err != nil {
return fmt.Errorf("unable to understand list result %#v (%v)", list, err)
}
initTrace.Step("Objects extracted")
// syncWith调用DeltaFIFO的Replace,用List的结果,替换DeltaFIFO中的内容
if err := r.syncWith(items, resourceVersion); err != nil {
return fmt.Errorf("unable to sync list result: %v", err)
}
initTrace.Step("SyncWith done")
r.setLastSyncResourceVersion(resourceVersion)
initTrace.Step("Resource version updated")
return nil
}(); err != nil {
return err
}
resyncerrc := make(chan error, 1)
cancelCh := make(chan struct{})
defer close(cancelCh)
// 下面是resync goroutine,就是将DeltaFIFO中的引用的knownObjects,(也就是本地缓存cache或者indexer),全部添加到
// DeltaFIFO中,并设置事件类型为sync。周期性的。
go func() {
resyncCh, cleanup := r.resyncChan()
defer func() {
cleanup() // Call the last one written into cleanup
}()
for {
select {
case <-resyncCh:
case <-stopCh:
return
case <-cancelCh:
return
}
if r.ShouldResync == nil || r.ShouldResync() {
klog.V(4).Infof("%s: forcing resync", r.name)
if err := r.store.Resync(); err != nil {
resyncerrc <- err
return
}
}
cleanup()
resyncCh, cleanup = r.resyncChan()
}
}()
// 这个是watch的循环,只有出错了才返回,返回之后listwatch要重新调用。
for {
select {
case <-stopCh:
return nil
default:
}
timeoutSeconds := int64(minWatchTimeout.Seconds() * (rand.Float64() + 1.0))
options = metav1.ListOptions{
ResourceVersion: resourceVersion,
TimeoutSeconds: &timeoutSeconds,
AllowWatchBookmarks: true,
}
// start the clock before sending the request, since some proxies won't flush headers until after the first watch event is sent
start := r.clock.Now()
// 调用listerWatcher的Watch方法
w, err := r.listerWatcher.Watch(options)
if err != nil {
if utilnet.IsConnectionRefused(err) {
time.Sleep(time.Second)
continue
}
return err
}
// 这个方法是阻塞式的,从watch接口的watch.Interface结果中,处理返回的事件
if err := r.watchHandler(start, w, &resourceVersion, resyncerrc, stopCh); err != nil {
if err != errorStopRequested {
switch {
case isExpiredError(err):
klog.V(4).Infof("%s: watch of %v closed with: %v", r.name, r.expectedTypeName, err)
default:
klog.Warningf("%s: watch of %v ended with: %v", r.name, r.expectedTypeName, err)
}
}
return nil
}
}
}
上面watchHandler是DeltaFIFO的生产者,收到事件之后,添加到DeltaFIFO中。
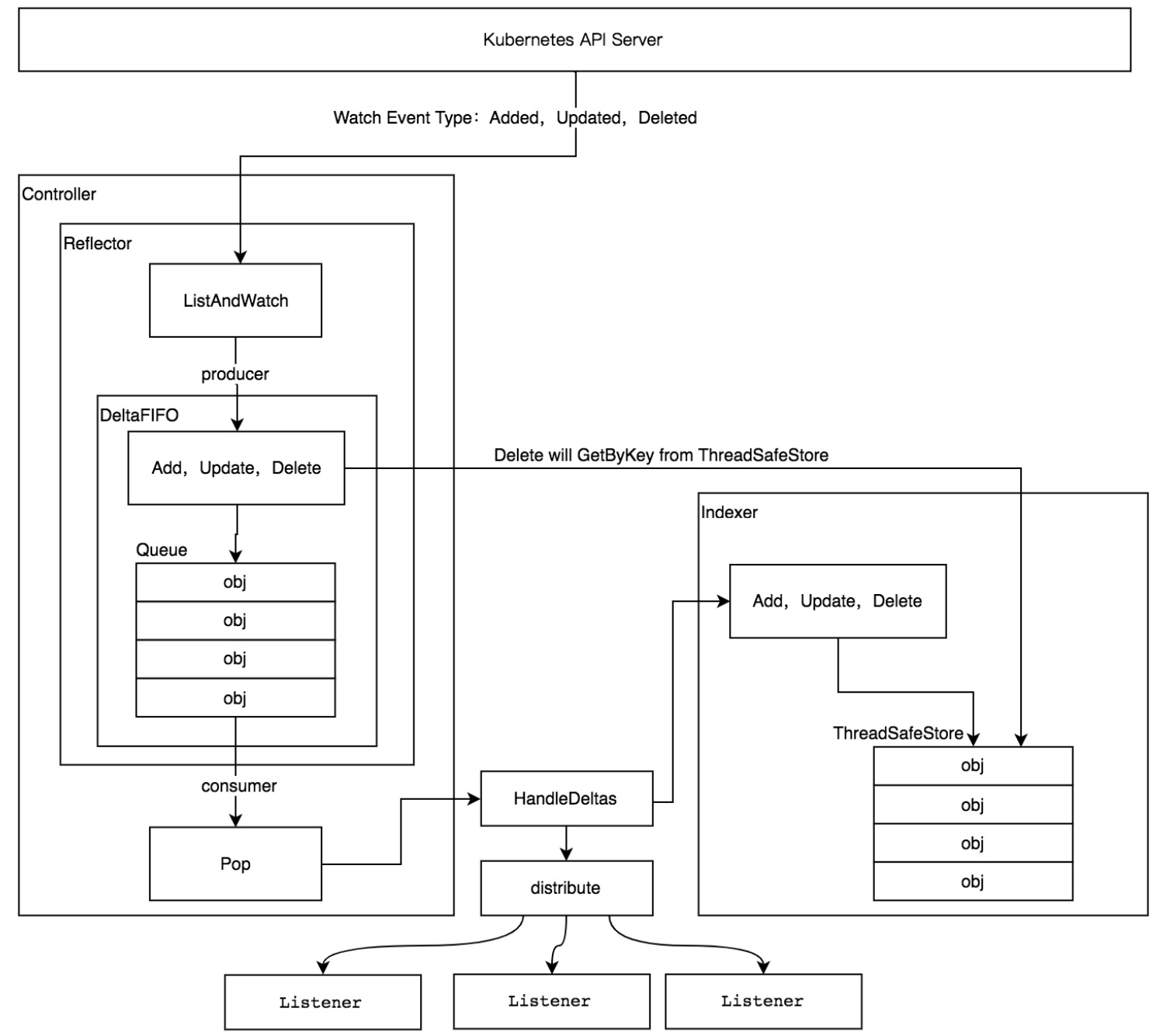
本文概述了Reflector的工作原理,最后从Kubernetes源码剖析中盗一张图: