虚拟地址空间概述
Linux 上进程使用的都是虚拟地址空间,再通过页表访问物理内存,其中虚拟地址空间的分布如下:
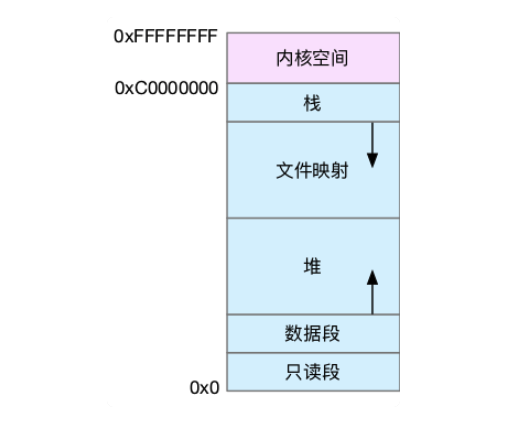 具体分为以下几部分:
具体分为以下几部分:
- 只读段:代码和和常量
- 数据段:全局变量
- 堆:动态分配的内存,从低地址开始向上增长
- 文件映射段:包括动态库、共享内存,从高地址到下增长
- 栈,包括局部变量和函数调用的上下文。栈的大小是固定的。
在 C 语言中,可以使用 malloc() 来申请内存,对应到操作系统上,有 brk() 和 mmap 两种调用方式,brk() 用于分配小内存(小于 128k),是通过移动堆顶的位置来分配内存。这些内存释放后,不会立刻归还给系统,而是缓存起来,这样就可以重复使用;大块内存(大于 128k),是通过内存映射 mmap 来分配,也就是在文件映射段找一块内存分配出去。当这两种调用发生时,其实并没有发生内存分配。这些内存,都只有在首次访问时才分配,也就是通过缺页异常进入内核中,再由内核来分配内存。
另外提一点 oom_score,进程的 oom_score 越大,进程越容易被 OOM 杀死。我们可以通过命令
echo -16 > /proc/$(pidof sshd)/oom_adj
来设置进程的 oom_score。
内存查看常用工具
free
[q@centos ~]$ free -h
total used free shared buff/cache available
Mem: 15G 7.8G 345M 1.6G 7.4G 3.8G
Swap: 8.0G 314M 7.7G
- total: 总内存
- used: 已使用的内存,包含共享内存
- free: 未使用的内存
- shared: 共享内存的大小
- buff/cache: 缓存和缓冲区的大小
- available: 新进程可用内存大小,available 不仅包含使用内存,还包括了可回收的缓存,所以一般会比未使用的内存更大。不过并不是所有的缓存都可以回收,因为有的缓存还在使用中。
其中 Buffer(buff) 是对磁盘数据的缓存,Cache(cache)是对文件数据的缓存,它们即会用在读请求,也会用在写请求中。
top
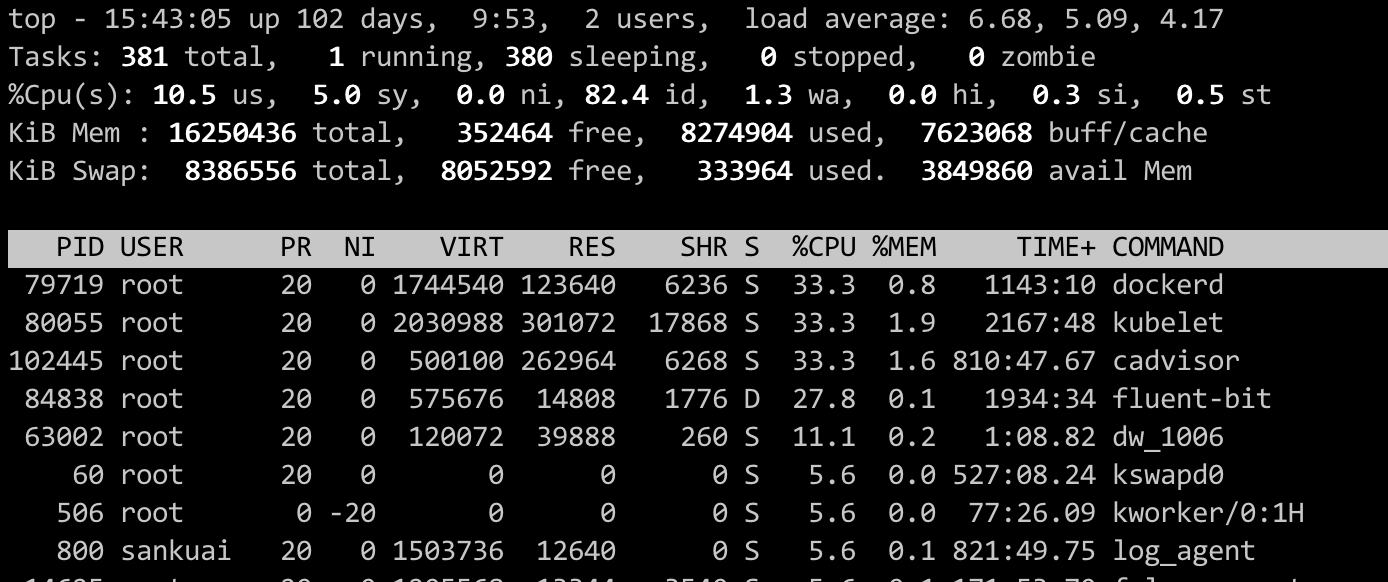
- VIRT: 进程虚拟内存大小,只要是进程申请过的内存,即便是没有真正分配的物理内存,也会计算在内。
- RES: 常驻内存大小,也就是进程实际使用的物理内存大小,但不包括 Swap 和共享内存。
- SHR: 共享内存大小,比如与其他进程共同使用的共享内存、加载的动态链接库以及程序的代码段。
- %MEM: 进程使用物理内存占系统总内存的百分比
vmstat
# 每隔1秒输出1组数据
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 7743608 1112 92168 0 0 0 0 52 152 0 1 100 0 0
0 0 0 7743608 1112 92168 0 0 0 0 36 92 0 0 100 0 0
- buff / cache: 跟 free 中的 buff 和 cache 一个含义,单位是 KB
- bi / bo: 分别表示块设备读取和写入的大小,单位为块/秒。因为 Linux 中块的大小为 1KB。所以这个单位也就等价于 KB/s.
cadvisor 容器监控
cadvisor中的rss
docker文档Metrics from cgroups: memory, CPU, block I/O解释了 rss 包含的内存:
| Metric | Description |
|---|---|
| rss | The amount of memory that doesn’t correspond to anything on disk: stacks, heaps, and anonymous memory maps. (rss 内存是不跟磁盘上的文件有关系的,区别于 cache) |
| cache | The amount of memory used by the processes of this control group that can be associated precisely with a block on a block device. When you read from and write to files on disk, this amount increases. This is the case if you use “conventional” I/O (open, read, write syscalls) as well as mapped files (with mmap). It also accounts for the memory used by tmpfs mounts, though the reasons are unclear. (cache 主要是跟磁盘上的文件有关系,并且包括了 tmpfs 内存) |
| active_anon, inactive_anon | The amount of anonymous memory that has been identified has respectively active and inactive by the kernel. “Anonymous” memory is the memory that is not linked to disk pages. In other words, that’s the equivalent of the rss counter described above. In fact, the very definition of the rss counter is active_anon + inactive_anon - tmpfs (where tmpfs is the amount of memory used up by tmpfs filesystems mounted by this control group). Now, what’s the difference between “active” and “inactive”? Pages are initially “active”; and at regular intervals, the kernel sweeps over the memory, and tags some pages as “inactive”. Whenever they are accessed again, they are immediately retagged “active”. When the kernel is almost out of memory, and time comes to swap out to disk, the kernel swaps “inactive” pages.(这里解释说,实际上 Anonymous 匿名内存基本跟 rss 是等价的,只不过要去掉 tmpfs 内存,后者是 tmpfs 文件系统消耗的,inactive 内存是指,这部分在使用之后,过了一段时间,被系统标记为不活跃,并且在 swap 内存到磁盘上时,首先 swap inactive 的内存。) |
| active_file, inactive_file | Cache memory, with active and inactive similar to the anon memory above. The exact formula is cache = active_file + inactive_file + tmpfs. The exact rules used by the kernel to move memory pages between active and inactive sets are different from the ones used for anonymous memory, but the general principle is the same. When the kernel needs to reclaim memory, it is cheaper to reclaim a clean (=non modified) page from this pool, since it can be reclaimed immediately (while anonymous pages and dirty/modified pages need to be written to disk first). (这里的 active_file 以及 inactibe_file 就是指 cache,活不活跃的判断,跟匿名内存是一致的。) |
cadvisor中的working-set
cadvisor 中,对 workingset 的注释为(根据注释看不出什么含义):
The amount of working set memory, this includes recently accessed memory, dirty memory, and kernel memory. Working set is <= “usage”.
不过根据代码能看出,workingset 是: usage - total_inactive_file
inactiveFileKeyName := "total_inactive_file"
if cgroups.IsCgroup2UnifiedMode() {
inactiveFileKeyName = "inactive_file"
}
workingSet := ret.Memory.Usage
if v, ok := s.MemoryStats.Stats[inactiveFileKeyName]; ok {
if workingSet < v {
workingSet = 0
} else {
workingSet -= v
}
}
ret.Memory.WorkingSet = workingSet
而根据 cgroup 的官方文档,文件 memory.usage_in_bytes的含义为:
For efficiency, as other kernel components, memory cgroup uses some optimization to avoid unnecessary cacheline false sharing. usage_in_bytes is affected by the method and doesn’t show ‘exact’ value of memory (and swap) usage, it’s a fuzz value for efficient access. (Of course, when necessary, it’s synchronized.) If you want to know more exact memory usage, you should use RSS+CACHE(+SWAP) value in memory.stat(see 5.2).
在 cadvisor 中,Usage 的定义如下:
type MemoryStats struct {
// Current memory usage, this includes all memory regardless of when it was
// accessed.
// Units: Bytes.
Usage uint64 `json:"usage"`
// Maximum memory usage recorded.
// Units: Bytes.
MaxUsage uint64 `json:"max_usage"`
// Number of bytes of page cache memory.
// Units: Bytes.
Cache uint64 `json:"cache"`
// The amount of anonymous and swap cache memory (includes transparent
// hugepages).
// Units: Bytes.
RSS uint64 `json:"rss"`
// The amount of swap currently used by the processes in this cgroup
// Units: Bytes.
Swap uint64 `json:"swap"`
// The amount of memory used for mapped files (includes tmpfs/shmem)
MappedFile uint64 `json:"mapped_file"`
// The amount of working set memory, this includes recently accessed memory,
// dirty memory, and kernel memory. Working set is <= "usage".
// Units: Bytes.
WorkingSet uint64 `json:"working_set"`
Failcnt uint64 `json:"failcnt"`
ContainerData MemoryStatsMemoryData `json:"container_data,omitempty"`
HierarchicalData MemoryStatsMemoryData `json:"hierarchical_data,omitempty"`
}
参考
[极客时间专栏:Linux性能优化-倪鹏飞]
Understanding Kubernetes Memory Metrics