文章目录
- 1.客户端发送请求
- 2.向 Raft 层发送 Propose 请求
- 3.Raft 通过 Ready 传递待持久化 Entry 和待发送的 MsgApp
- 4.EtcdServer 处理 Ready
- 5.已写入 wal 的 Entry 可写入 MemoryStorage
- 6.Raft 处理 MsgAppResp 消息,计算 commitedIndex
- 7.EtcdServer 获取已经 committed 的 Entries
- 8.EtcdServer 调用 backend apply 数据
- 参考
唐聪(腾讯云资深工程师)在极客时间专栏《etcd 实战课》中,大概介绍了一下 Etcd 的日志复制流程,并画了一个很好的图,本文参考这个图,顺藤摸瓜分析代码,再研究下日志复制流程,之前写过一些大概流程,相对于之前的文章,这里更关注一些 index 更新的细节问题。
在 Leader 收到 put 请求后,向 Follower 节点复制日志的整体流程图,下面每个核心流程都有序号,下面有根据每个序号再分析下,目标是将整个流程都串联起来。下图中,绿色的 Raft State Machine 是 raft 层实现,Leader B 是 EtcdServer 实现,也就是 raft 的应用层。
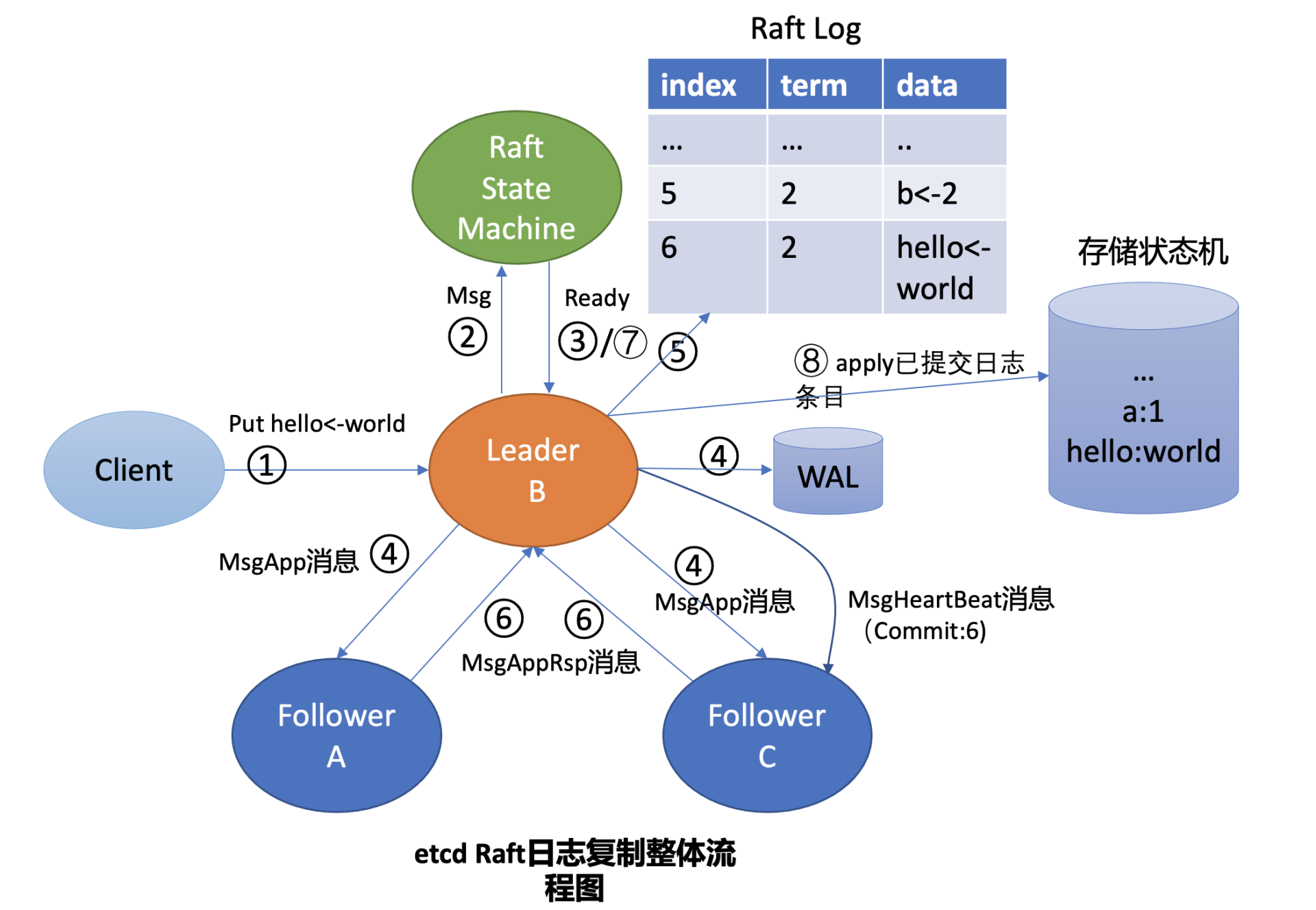
1.客户端发送请求
客户端通过 clientv3 发送 put 请求,这部分可以参考《Etcd put 请求过程:clientv3 发送请求到 EtcdServer》
2.向 Raft 层发送 Propose 请求
EtcdServer 在收到 put 请求后,向 raft 层发送 propose 请求,raft 层收到这个请求后,主要做两件事:1)将消息添加到 unstable storage 中;2)为每个 follower 生成 MsgApp 消息,并通过 Ready 结构体将这个消息返回给上层 EtcdServer。参考《Etcd put 请求过程:EtcdServer 处理概述》
这里还有个问题需要注意,新添加的 Entry 的 index 是怎么确认的?
对于新增的 Entry,从 unstable 里获取 index(只要有任意一个 Entry 或者 snapshot),由此可见 unstable 存储里的 Entry 总是最新的,下面 appendEntry 是将 Entry 添加到 unstable 时确定 index 的代码。如果 unstable 为空则从 MemoryStorage 里获取 index,其确定 index 的代码为 ms.ents[0].Index + uint64(len(ms.ents)) - 1.
// etcd/raft/log.go
func (r *raft) appendEntry(es ...pb.Entry) (accepted bool) {
li := r.raftLog.lastIndex()
for i := range es {
es[i].Term = r.Term
es[i].Index = li + 1 + uint64(i)
}
// ...
return true
}
// 根据 unstable 里的内容确定 lastIndex
func (l *raftLog) lastIndex() uint64 {
if i, ok := l.unstable.maybeLastIndex(); ok {
return i
}
i, err := l.storage.LastIndex()
if err != nil {
panic(err) // TODO(bdarnell)
}
return i
}
2.1 MsgApp 消息具体内容
构造 MsgApp 消息是在 maybeSendAppend 方法中的,下面参数中的 to 表示要发送给哪个 follower,每个 follower 都在 visit 遍历方法中发送一边,sendIfEmpty 表示没有 Entry 要不要发送消息。我们去繁就简看下消息的具体内容,其中:
// etcd/raft/raft.go
func (r *raft) maybeSendAppend(to uint64, sendIfEmpty bool) bool {
m := pb.Message{}
// To 表示消息接收者
m.To = to
// 已经发送的最大消息的 term
term, errt := r.raftLog.term(pr.Next - 1)
// 取所有还没有发送的消息,这个 maxMsgSize 默认是 1024*1024,足够大
ents, erre := r.raftLog.entries(pr.Next, r.maxMsgSize)
//...
// 消息的类型为 MsgApp
m.Type = pb.MsgApp
// 消息的 Index 为,已发送的最大的 index
m.Index = pr.Next - 1
m.LogTerm = term
// 还没有发送的 entry
m.Entries = ents
// 当前leader,已经 commit 的 索引
m.Commit = r.raftLog.committed
}
r.send(m)
return true
}
在 Etcd 中,用结构体
Progress来表示每个 follower 的进度(也就是上面代码中的pr),其中next属性表示下一条要发送的 Entry 的序号,next 之前的都发送过了。match属性表示 follower 已经拷贝的 Entry 序号。
3.Raft 通过 Ready 传递待持久化 Entry 和待发送的 MsgApp
保存在 unstable storage 的 Entry 和 Msg 都会通过 Ready 返回给 Server。
// etcd/raft/node.go
func newReady(r *raft, prevSoftSt *SoftState, prevHardSt pb.HardState) Ready {
rd := Ready{
// 保存在临时存储中的 Entry
Entries: r.raftLog.unstableEntries(),
CommittedEntries: r.raftLog.nextEnts(),
// 待发送的消息
Messages: r.msgs,
}
// ...
return rd
}
4.EtcdServer 处理 Ready
EtcdServer 收到消息后,发送 MsgApp 消息,并将 Entry 写到 wal,参考《Etcd 中的 wal 处理流程》
// etcd/etcdserver/raft.go
func (r *raftNode) start(rh *raftReadyHandler) {
// ...
// 发送消息
if islead {
r.transport.Send(r.processMessages(rd.Messages))
}
// 将 unstable 存储中的 Entry 写 wal
if err := r.storage.Save(rd.HardState, rd.Entries); err != nil {
// ...
}
}
4.1 follower 处理 MsgApp 消息
这里顺便看下 follower 是怎么处理 MsgApp 消息的,我们已经在 2.1 章节分析了 MsgApp 消息的格式。其中 m.Index 是消息中的最小的 Index-1(对于 leader 来说是 next-1),m.Commit 是 leader 已经 commit 的序号。在 follower 的处理中,主要还是添加 Entry 到 unstable 存储中,其后面的处理就跟 leader 一致了,比如由应用层写 wal 等。
func (r *raft) handleAppendEntries(m pb.Message) {
// follower 记录的 committed index 已经大于 msg 发送过来的最小 index,旧消息
if m.Index < r.raftLog.committed {
r.send(pb.Message{To: m.From, Type: pb.MsgAppResp, Index: r.raftLog.committed})
return
}
// 这里将消息拷贝到 unstable 存储,返回的 mlastIndex 是完成拷贝的最大的 Entry
if mlastIndex, ok := r.raftLog.maybeAppend(m.Index, m.LogTerm, m.Commit, m.Entries...); ok {
r.send(pb.Message{To: m.From, Type: pb.MsgAppResp, Index: mlastIndex})
} else {
// 处理失败...
}
}
func (l *raftLog) maybeAppend(index, logTerm, committed uint64, ents ...pb.Entry) (lastnewi uint64, ok bool) {
if l.matchTerm(index, logTerm) {
lastnewi = index + uint64(len(ents))
ci := l.findConflict(ents)
switch {
case ci == 0:
case ci <= l.committed:
l.logger.Panicf("entry %d conflict with committed entry [committed(%d)]", ci, l.committed)
default:
offset := index + 1
// 这里是添加到本地 unstable 存储
l.append(ents[ci-offset:]...)
}
// 对于 follower 来说,committed 标志是 min{leader的commit序号,已复制的 entry 最大序号}
l.commitTo(min(committed, lastnewi))
return lastnewi, true
}
return 0, false
}
follower 处理完 AppMsg 之后,返回一个 AppMsgResp 消息,在这个消息中,Index 表示 follower 已经复制的最大的Index,从代码里看,这里的已复制是指写到 unstable 存储。
5.已写入 wal 的 Entry 可写入 MemoryStorage
MemoryStorage 在 raft 层中扮演一个 Entry 数据库的角色,可对 Entry 进行查询,MemoryStorage 中保存了全量的 Entry,请求 FirstIndex() 之前的 Entry 会报 ErrCompacted 错误,其实现的 Storage 接口入下。
type Storage interface {
InitialState() (pb.HardState, pb.ConfState, error)
// 返回位于区间 [lo, hi) 的 Entry,最多返回 maxSize 哥
Entries(lo, hi, maxSize uint64) ([]pb.Entry, error)
// 返回 term i 的任期
Term(i uint64) (uint64, error)
LastIndex() (uint64, error)
FirstIndex() (uint64, error)
// 返回最近的快照
Snapshot() (pb.Snapshot, error)
}
EtcdServer 在将日志写入 wal 后,便将 Entry 写入 MemoryStorage,(由此可见,MemoryStorage 中的 Entry 有可能没有 Commited)
// etcd/etcdserver/raft.go
r.raftStorage.Append(rd.Entries)
上述 Append 方法是将 rd.Entries 跟 MemoryStorage 中的 Entry 合并,合并的时候可能需要去重,具有相同 index 的Entry 只保留一个。
func (ms *MemoryStorage) Append(entries []pb.Entry) error {
// MemoryStorage 中的第一个 Index
first := ms.firstIndex()
// 新增 Entry 的 last
last := entries[0].Index + uint64(len(entries)) - 1
if last < first {
return nil
}
// truncate compacted entries
// 这个成立的条件是保证 Entry 是连续的
if first > entries[0].Index {
entries = entries[first-entries[0].Index:]
}
offset := entries[0].Index - ms.ents[0].Index
switch {
case uint64(len(ms.ents)) > offset:
ms.ents = append([]pb.Entry{}, ms.ents[:offset]...)
ms.ents = append(ms.ents, entries...)
case uint64(len(ms.ents)) == offset:
ms.ents = append(ms.ents, entries...)
// ...
}
return nil
}
6.Raft 处理 MsgAppResp 消息,计算 commitedIndex
在 MsgAppResp 消息中,最重要的属性是 Index,表示 follower 已经复制的最大 Index。处理 MsgAppResp 消息还是在 stepLeader 方法中,我们只关注 MsgAppResp 消息的处理。在下面代码中,最重要的是 MaybeUpdate 方法以及 maybeCommit 方法。其中:
- MaybeUpdate: 表示一个 follower(即消息的发送者)match index 要不要更新,如果需要更新,则更新,并放回true
- maybeCommit: 重新计算所有 follower 的 match index(这个计算方式有点复杂,我现在还没看懂),如果 CommittedIndex 增大了,则更新 raftlog.CommittedIndex 标志,并广播一个 MsgApp 消息,用于 follower 更新 commited 标志。
// etcd/raft/raft.go
func stepLeader(r *raft, m pb.Message) error {
// ...
pr := r.prs.Progress[m.From]
if pr == nil {
r.logger.Debugf("%x no progress available for %x", r.id, m.From)
return nil
}
switch m.Type {
case pb.MsgAppResp:
pr.RecentActive = true
if m.Reject {
// handle rejected
} else {
oldPaused := pr.IsPaused()
// 这里的 MaybeUpdate 返回 true,如果 leader 记录的 match 小于 follower 已经复制的 index
// 并且同时更新 follower 的 match
if pr.MaybeUpdate(m.Index) {
// 计算最大的 committed index,如果有变化,则 bcastAppend
if r.maybeCommit() {
r.bcastAppend()
} else if oldPaused {
r.sendAppend(m.From)
}
}
}
// ...
}
return nil
}
7.EtcdServer 获取已经 committed 的 Entries
已经 committed Entry 同样是通过 Ready 传递给应用层的,从下面代码中可以看出,需要 apply 的所有 Entry 即 Ready 中的 CommittedEntries 结构体,而这部分内容在构造时,是通过 r.raftLog.nextEnts() 方法拿到的。我们看下这个方法是怎么实现的。
// etcd/etcdserver/raft.go
func (r *raftNode) start(rh *raftReadyHandler) {
go func() {
for {
select {
case <-r.ticker.C:
case rd := <-r.Ready():
notifyc := make(chan struct{}, 1)
ap := apply{
// 获取 committedEntries
entries: rd.CommittedEntries,
snapshot: rd.Snapshot,
notifyc: notifyc,
}
select {
case r.applyc <- ap: // 将 apply 结构体写入 channel,消费者取 apply 进行应用
case <-r.stopped:
return
}
}
}
}
}
// etcd/raft/node.go
func newReady(r *raft, prevSoftSt *SoftState, prevHardSt pb.HardState) Ready {
rd := Ready{
// 保存在临时存储中的 Entry,待写 wal
Entries: r.raftLog.unstableEntries(),
// 已经 committed,待 apply 的 Entries
CommittedEntries: r.raftLog.nextEnts(),
// 待发送的消息
Messages: r.msgs,
}
// ...
return rd
}
概括来讲,raftLog.nextEnts() 做的事情就是从存储中获取区间 [applied+1, committed] 中的所有 Entry,其代码如下,一般来说 applied+1 是要大于 firstIndex() 的,如果 applied+1 小于 firstIndex()那就从后者开始 apply,因为[applid+1, firstIndex) 这个区间的 Entrys 已经被 compacted 了,不需要 apply。
func (l *raftLog) nextEnts() (ents []pb.Entry) {
off := max(l.applied+1, l.firstIndex())
if l.committed+1 > off {
ents, err := l.slice(off, l.committed+1, l.maxNextEntsSize)
if err != nil {
l.logger.Panicf("unexpected error when getting unapplied entries (%v)", err)
}
return ents
}
return nil
}
在取区间内的 Entries 时,首先对边界进行了检查,其中对 lo 和 hi 的要求为:
- lo: lo 不能比
raftLog.firstIndex()要小,其中firstIndex()的计算方式为:1)如果 unstable 存储有 snapshot,则为snapshot.Metadata.Index + 1,否则,2)为 MemoryStorage 的 firstIndex。如果比 firstIndex 小会报ErrCompacted错误。假设正常情况下 unstable 没有 snapshot(其来源是 MsgSnap),由此可见系统中最小的可用 Index 就是 MemoryStorage 的Index。 - hi: hi 不能大于
lastIndex()+1,raftLog 计算 lastIndex()的优先级为:1)unstable 的 Entry;2)unstable 的 snapshot; 3)memoryStorage 的lastIndex()。由此可见,unstable 总是比 MemoryStroage 要信的。
另外从下面代码中可以看出,取待 apply 的消息时,有可能从 MemoryStorage 中获取,也有可能从 unstable 中获取。
func (l *raftLog) slice(lo, hi, maxSize uint64) ([]pb.Entry, error) {
err := l.mustCheckOutOfBounds(lo, hi)
var ents []pb.Entry
if lo < l.unstable.offset {
// 从 MemoryStorage 中取
storedEnts, err := l.storage.Entries(lo, min(hi, l.unstable.offset), maxSize)
ents = storedEnts
}
if hi > l.unstable.offset {
// 从 unstable 中取
unstable := l.unstable.slice(max(lo, l.unstable.offset), hi)
}
return limitSize(ents, maxSize), nil
}
8.EtcdServer 调用 backend apply 数据
EtcdServer 在启动时,会有一个无限 for 循环,不停的消费 raftNode.applyc 这个 channel,并从中读取可以被 apply 的 Entry,并进行 apply。
// etcd/etcdserver/server.go
func (s *EtcdServer) run() {
sched := schedule.NewFIFOScheduler()
// 启动 raftnode
s.r.start(rh)
// ...
for {
select {
case ap := <-s.r.apply():
// raftNode.applyc channel 中读取待 apply 的消息,进行 apply
f := func(context.Context) { s.applyAll(&ep, &ap) }
sched.Schedule(f)
}
}
}
apply 完成之后,整个请求结束,返回结果给 client,这里还有个很精巧的设计,我们知道之前的put 请求被阻塞在一个 wait map 中去了,这里调用了 wait 的 trigger 解除之前的阻塞,这个设计有时间也研究一下,也就是下面 wait 的设计。
// etcd/pkg/wait/wait.go
type Wait interface {
// Register waits returns a chan that waits on the given ID.
// The chan will be triggered when Trigger is called with
// the same ID.
Register(id uint64) <-chan interface{}
// Trigger triggers the waiting chans with the given ID.
Trigger(id uint64, x interface{})
IsRegistered(id uint64) bool
}
总结,处理 put 请求,大概有 8 个大步骤,这里分析了 8 个步骤的相关代码,总的来说有些细节还没有扣清楚,比如 snapshot 的更新机制,apply 的流程,这个有时间再分析下。