前几天在跟同事沟通的时候,提到了一种 pod 优雅退出的实现方式是在 preStop hook 中 sleep 几秒,主要是 service 摘除 pod 的 endpoint 有时延,pod 退出之后可能还有流量打进来,sleep 的目的是给 Controller manager 中的 endpoint controller 足够的时间来删除特定 pod 的 endpoint。这里涉及到好几个组件,本文总结下这几个组件的交互流程。
本文考虑的是 K8s 层面的优雅退出,主要是从服务注册中心反注册这件事,应用程序的优雅退出,比如 http server、db server 暂不考虑
使用 hook 的例子:
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
preStop:
exec:
command: ["/bin/sh","-c","nginx -s quit; while killall -0 nginx; do sleep 1; done"]
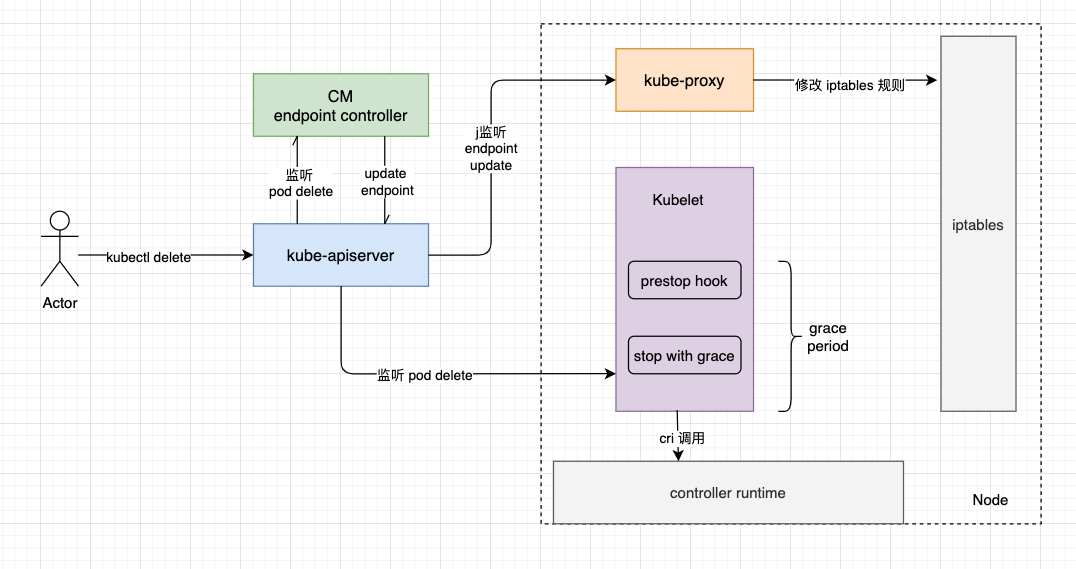
在 prestop hook 设置为 sleep 5 情况下,一个 pod 删除的流程大概如下图,其中 endpoint controller kube-proxy kubelet 都是并发工作的,相互之间不存在依赖关系,只监听 apiserver 事件。
当我们使用 kubectl delete 删除pod,或者使用 client-go 删除时,只是配置了一下这个 pod 的 deleteTimestamp,并配置了一个 grace period,我们假设为 30s。
这里再补充点其他内容,发送 delete 请求的时候,对应资源的 controller informer 收到的是一个 update 事件,这个 update 事件就是给对应的资源配置了一个 deletionTimestamp 以及 deletionGracePeriodSeconds,(此时的 pod 状态是 terminating,还未删除),还未收到 delete 事件,后者在从数据库删除时才会有事件发出来。
下面简述下三个组件的工作流程
endpoint controller
endpoint 在监听 pod update 事件(deletionTimeStamp 不为空),然后通过 serviceLister 从缓存获取该 pod 所对应的 service,(serviceLister 有api做这个事情,大概思路是获取 pod ns 下的所有 service,然后看看 service 的 label 跟 pod label 是否匹配)。
将 service 名字放入队列(其实这个是 endpoint 队列,因为 endpoint 跟 service 是同名的),在处理函数中,再通过这个 service 拉取该 service 对应的 pod 列表,如果 pod 的 deletionTimeStamp 不为 nil,则不追加这个 pod 的 ip 为 endpoint address。
处理完成之后,决定要不要 update endpoint,如果 pod 被删除了,那肯定是要的。
kubelet
kubelet 处理稍微复杂一点,kubelet 在发现 deletionTimeStamp 不为空之后,开始 kill pod,在 kill pod 之前先执行 prestop hook,执行完 prestop hook 之后才调用 cri 的 StopContainer 接口。
下面是 syncPod 中的代码,开始处理删除操作。
// Kill pod if it should not be running
if !runnable.Admit || pod.DeletionTimestamp != nil || apiPodStatus.Phase == v1.PodFailed {
var syncErr error
if err := kl.killPod(pod, nil, podStatus, nil); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToKillPod, "error killing pod: %v", err)
syncErr = fmt.Errorf("error killing pod: %v", err)
utilruntime.HandleError(syncErr)
} else {
if !runnable.Admit {
// There was no error killing the pod, but the pod cannot be run.
// Return an error to signal that the sync loop should back off.
syncErr = fmt.Errorf("pod cannot be run: %s", runnable.Message)
}
}
return syncErr
}
下面是 kubeGenericRuntimeManager) killContainer 的逻辑,可以看到,一开始执行 prestop hook 的时候,容器还是运行的,此时业务程序还在该干嘛干嘛,也没有收到 SIGTERM 信号。等到 executePreStopHook 返回之后,才调用 StopContainer 发送 SIGTERM 信号给应用,不过 gracePeriod 参数变短了,要扣除 prestop hook 执行的时间。这里最低的 gracePeriod 是 2 秒,不可能是负数或者 0.
// Run the pre-stop lifecycle hooks if applicable and if there is enough time to run it
if containerSpec.Lifecycle != nil && containerSpec.Lifecycle.PreStop != nil && gracePeriod > 0 {
gracePeriod = gracePeriod - m.executePreStopHook(pod, containerID, containerSpec, gracePeriod)
}
// always give containers a minimal shutdown window to avoid unnecessary SIGKILLs
if gracePeriod < minimumGracePeriodInSeconds {
gracePeriod = minimumGracePeriodInSeconds
}
if gracePeriodOverride != nil {
gracePeriod = *gracePeriodOverride
klog.V(3).Infof("Killing container %q, but using %d second grace period override", containerID, gracePeriod)
}
klog.V(2).Infof("Killing container %q with %d second grace period", containerID.String(), gracePeriod)
err := m.runtimeService.StopContainer(containerID.ID, gracePeriod)
我们再来看下 hook 是怎么执行的,通过下面代码看到,hook 是在一个单独的 goroutine 里执行的,executePreStopHook 这个方法通过 gracePeriod 设置了一个超时,方法一旦超时就返回,不管这个 goroutine 执行到哪里了,(如果没有执行完,还是在后台执行,不过因为 kubelet 会杀掉容器,所以 hook 是有可能没执行完就被干掉了)
// executePreStopHook runs the pre-stop lifecycle hooks if applicable and returns the duration it takes.
func (m *kubeGenericRuntimeManager) executePreStopHook(pod *v1.Pod, containerID kubecontainer.ContainerID, containerSpec *v1.Container, gracePeriod int64) int64 {
klog.V(3).Infof("Running preStop hook for container %q", containerID.String())
start := metav1.Now()
done := make(chan struct{})
go func() {
defer close(done)
defer utilruntime.HandleCrash()
if msg, err := m.runner.Run(containerID, pod, containerSpec, containerSpec.Lifecycle.PreStop); err != nil {
klog.Errorf("preStop hook for container %q failed: %v", containerSpec.Name, err)
m.recordContainerEvent(pod, containerSpec, containerID.ID, v1.EventTypeWarning, events.FailedPreStopHook, msg)
}
}()
select {
case <-time.After(time.Duration(gracePeriod) * time.Second):
klog.V(2).Infof("preStop hook for container %q did not complete in %d seconds", containerID, gracePeriod)
case <-done:
klog.V(3).Infof("preStop hook for container %q completed", containerID)
}
return int64(metav1.Now().Sub(start.Time).Seconds())
}
kube-proxy
kube-proxy 监听 endpoint,通过 endpoint 来刷新 iptables 规则(假设 service 的代理方式为 iptables),在 K8s 中如果使用 service 来做服务发现,coredns 将 service 解析为 clusterIP,在节点的 iptables 规则中,再重定向 clusterIP 到具体的 pod ip,所以,kube-proxy 刷新 iptables 规则也是很重要的。如果 pod 删除了,那对应的 iptables 规则就要删除,请求才不会发过去。
所以 kube-proxy 还是要等 endpoint controller 把 endpoints 更新之后,才去刷新 iptables 规则。
其他
Kubernetes 中如何保证优雅地停止 Pod 中提高了一种通过 validationwebhook 一直拒绝的方式,不过感觉使用 finalizer 更优雅一点?