目录
keda 概述
keda 是开源的基于 K8s 自动扩缩容解决方案,相对于原生 hpa,其支持的事件类型更为丰富,官方网站 Scalers 列举了其支持的事件源以及配置方式,本文会以 mysql 事件源为例说明 keda 的工作过程。
根据 How KEDA works,keda 的架构如下图所示。从下图中可以看到 keda 主要提供了四个组件:1)Metrics adapter,角色跟 metrics-server 类似,提供了众多供 hpa 使用的指标;2)Controller 部分;3)Scaler,处理外部事件;4)Webhooks 用于校验。
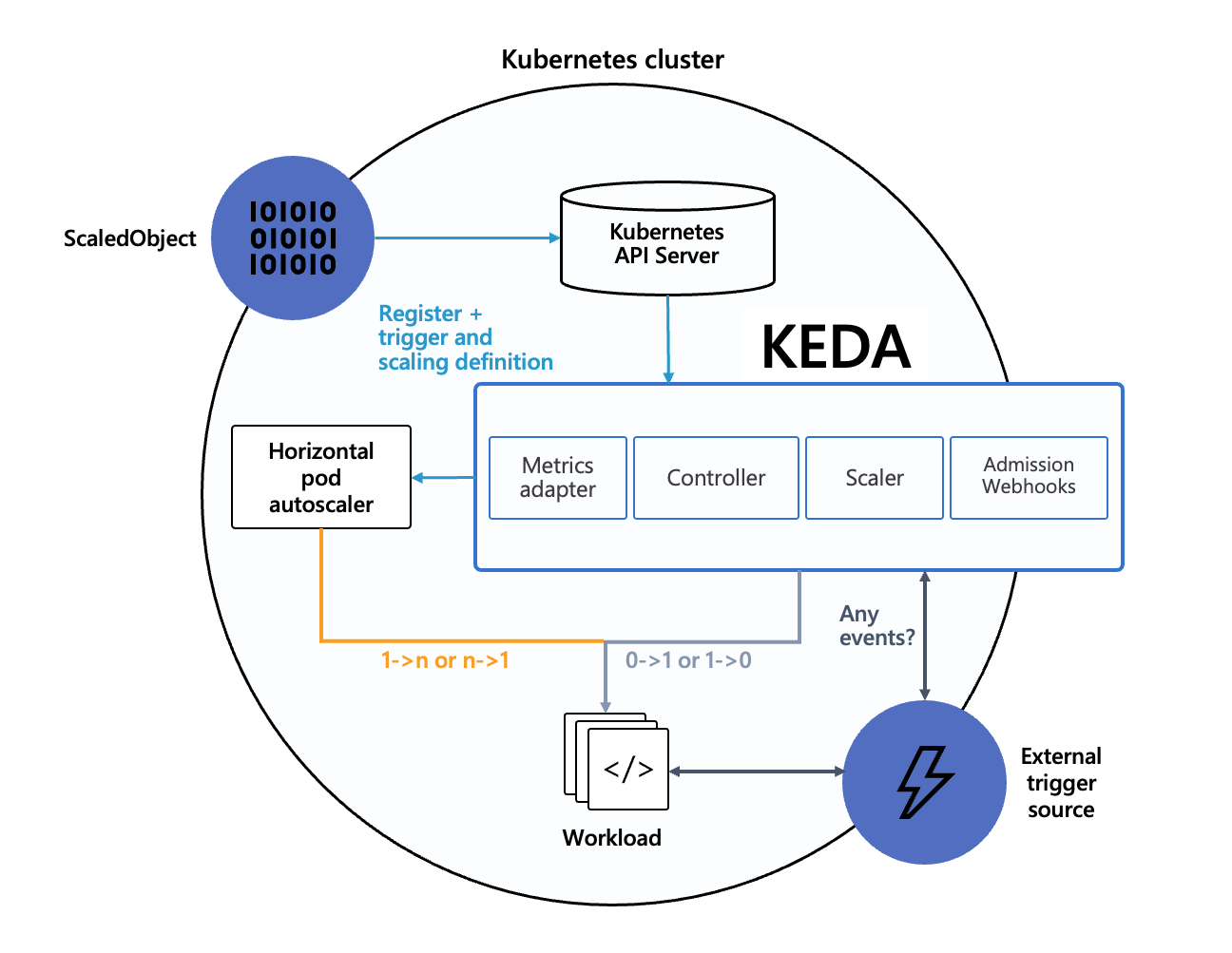 keda 主要引入的 crd 是 ScaledObject,扩缩容的配置需要是围绕 ScaledObject 展开的。另外 keda 还支持从 0 副本扩容到 1 副本,以及从 1 副本缩容到 0 副本。
keda 主要引入的 crd 是 ScaledObject,扩缩容的配置需要是围绕 ScaledObject 展开的。另外 keda 还支持从 0 副本扩容到 1 副本,以及从 1 副本缩容到 0 副本。
安装 keda
通过 helm 安装。安装完成后,会启动三个 pod。
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
helm install keda kedacore/keda --namespace keda --create-namespace
快速入手(以mysql为例)
本小节会以 mysql 为例子演示下 keda 的配置及工作过程,keda 关于 mysql 的配置文档为 mysql scaler。为了将 mysql 作为事件源,我们需要安装一个 mysql。可以通过 helm 安装。
helm install my-release oci://registry-1.docker.io/bitnamicharts/mysql
为了模拟业务,我们创建一个 connections 表,表中记录当前业务服务器所处理的所有连接,然后在 connections 表行数比较多的时候,会触发扩容以缓解业务压力。connections 表中只有一个字段 state,表示连接状态,简单起见,我们只会把这个 state 设置为 running。通过下面语句创建数据库与表。
create database keda;
CREATE TABLE connections (
id INT AUTO_INCREMENT PRIMARY KEY,
state VARCHAR(100) NOT NULL
);
我们通过一个 nginx deployment 来模拟业务,当 connections 较多时,会触发 deployment 扩缩容,我们先部署 deployment。一开始的时候,副本数设置为 0,期望 keda 会激活 deployment,并进行扩容。
a. 创建 deployment,初始副本数为 0。
apiVersion: apps/v1
kind: Deployment
metadata:
name: worker
namespace: my-project
labels:
app: nginx
spec:
replicas: 0
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
b. 创建 ScaledObject。下面的配置中 secret 里配置了连接 mysql 用的连接串,其内容格式为 user:password@tcp(mysql-host:3306)/keda,需要配置为 base64 编码后配置到 mysql_conn_str 中。另外需要关注 triggers 部分 metadata 部分的配置,一共有三个:1)queryValue:每个副本需要处理的连接数。2)activationQueryValue:激活业务需要的连接数,这里设置为 0.1 有点牵强,表示只要有连接就要激活;3)query: sql查询语句,这个需要需要返回一个数值,表示当前连接总数。结合我们的配置,所期望达到的效果是:平均每个 nginx 副本需要处理两个连接。
apiVersion: v1
kind: Secret
metadata:
name: mysql-secrets
namespace: my-project
type: Opaque
data:
mysql_conn_str: cm9vdDp1WWlwc1VSVWxkQHRjcCgxMC45Ni4xMjkuODc6MzMwNikva2VkYQ==
---
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: keda-trigger-auth-mysql-secret
namespace: my-project
spec:
secretTargetRef:
- parameter: connectionString
name: mysql-secrets
key: mysql_conn_str
---
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: mysql-scaledobject
namespace: my-project
spec:
scaleTargetRef:
name: worker
triggers:
- type: mysql
metadata:
queryValue: "2"
activationQueryValue: "0.1"
query: "select count(*) from connections where state='running';"
authenticationRef:
name: keda-trigger-auth-mysql-secret
另外,因为 keda 是通过原生 hpa 来进行副本扩缩容的,我们可以看下 keda 帮忙生成 hpa 配置:
spec:
maxReplicas: 100
metrics:
- external:
metric:
name: s0-mysql-keda
selector:
matchLabels:
scaledobject.keda.sh/name: mysql-scaledobject
target:
averageValue: "2"
type: AverageValue
type: External
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: worker
c. 往数据库表 connections 中插入一条记录,查看扩缩容情况。
INSERT INTO connections (state) VALUES ('running');
此时表中仅有一行记录。根据我们的配置,此时来了一个连接,keda 应该会帮我们对 deployment 进行激活,现象如下。describe scaledObject,发现触发了 deployment 的扩容。
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal KEDAScalersStarted 3m28s keda-operator Scaler mysql is built.
Normal KEDAScalersStarted 3m28s keda-operator Started scalers watch
Normal ScaledObjectReady 3m28s keda-operator ScaledObject is ready for scaling
Normal KEDAScaleTargetActivated 28s keda-operator Scaled apps/v1.Deployment my-project/worker from 0 to 1, triggered by mySQLScaler
d. 继续往 connections 中插入数据。
a) 当 connections 中一共有两条记录时,不会触发扩容,因为平均连接数还是 2。
b) 当 connections 中一共有三条记录时,会发生扩容,平均连接数不是 2 了。
mysql> INSERT INTO connections (state) VALUES ('running');
Query OK, 1 row affected (0.01 sec)
mysql> select count(*) from connections where state="running";
+----------+
| count(*) |
+----------+
| 3 |
+----------+
1 row in set (0.00 sec)
我们查看 pods 数,确实发生了扩容。
lr90@sj keda % kubectl get pods -n my-project
NAME READY STATUS RESTARTS AGE
worker-7fb96c846b-9mkkv 1/1 Running 0 102s
worker-7fb96c846b-fb7d4 1/1 Running 0 14m
c) 当 connections 表中有四条记录时,不会触发扩容。
keda 的一些特性
缩容到 0
在 keda 中,从 0 副本扩容到 1 副本的过程称为激活。 我们上面的示例中也说明了这个过程。另外 keda 有配置 idleReplicaCount 也能说明这个过程,根据官方文档这个值目前只能被设置为 0。当没有业务时 keda 会将这个副本数设置为这个值,如果业务来了,会先将副本数从 idleReplicaCount 调整为 minReplicaCount,这个过程是 keda 负责的,称为激活,调整为 minReplicaCount 之后,就由 hpa 负责了,在 [minReplicaCount, maxReplicaCount] 之间波动。
定时扩缩容
基于事件的扩缩容,一般都会存在延时,也就是滞后性,一些业务带有明显的波峰和波谷,对于这种类型的业务,可以使用定时扩缩容功能。keda 支持 Corn 类型的 trigger,其配置为:
triggers:
- type: cron
metadata:
# Required
timezone: Asia/Kolkata # The acceptable values would be a value from the IANA Time Zone Database.
start: 0 6 * * * # At 6:00 AM
end: 0 20 * * * # At 8:00 PM
desiredReplicas: "10"
上述配置表示在 6 点到 8 点时间段保持 10 个副本。
总体来看 keda 的定时扩缩容感觉不是很灵活,至少保持 10 个副本可能存在资源浪费,华为的《通过HPA+CronHPA组合应对业务复杂弹性伸缩场景》提供了一种思路:定时调整 hpa 的最小副本数,来实现定时扩缩容的目标。可通过一个额外的控制器来实现,需要注意的是控制器要调整的是 hpa CR 而不是 deployment,这是为了防止与 hpa 控制器相互冲突,这一点跟 keda 是类似的,都是借助原生 hpa 来实现扩缩容。
事件驱动,事件源丰富
keda 支持很多事件源,具体可以参考文档 Scalers。
一些参考
openkruise 基于HPA的极致弹性调度最佳实践
《基于HPA的极致弹性调度最佳实践》 这个是 openkruise 写的一篇技术实践,其总体架构如下,在该方案中,keda 通过 prometheus 采集 Ingress Nginx 的指标,原生 nginx 的指标,prometheus 是无法采集的,这里通过 Nginx-Prometheus-Exporter 开源组件进行适配,使 prometheus 能够采集 nginx 指标。
在该方案中,keda 扩缩容的对象为 CloneSet,只要实现了 scale subresource 的资源都可以跟 hpa 协助来进行自动扩缩容。
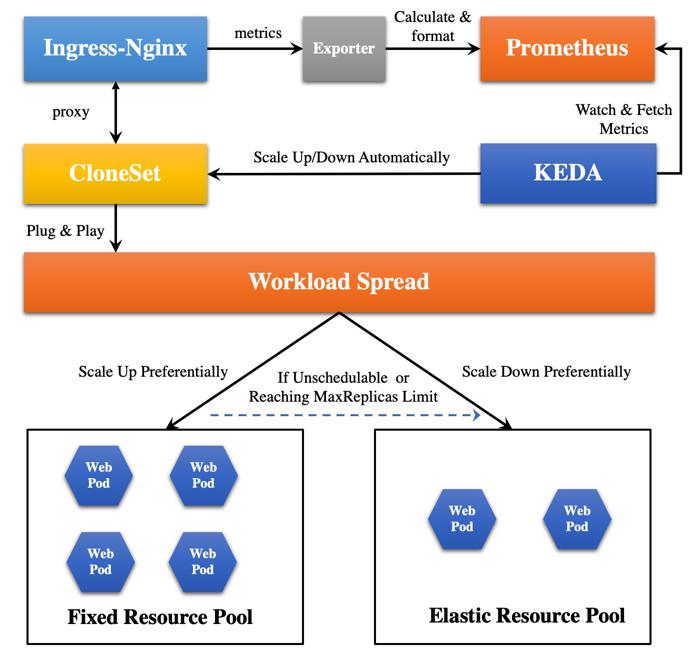
因为使用了 prometheus 作为指标来源,其 ScaledObject 配置如下,所使用的 prometheus 查询语句为 sum(rate(nginx_http_requests_total{job="ingress-nginx-exporter"}[12s])),表示所有带有 job="ingress-nginx-exporter" 的请求增长率。prometheuse trigger 的其他配置参数有:1)serverAddress: prometheus 服务器的地址;2)metricName: 指标名称;3)threshold: 触发扩容的阈值。
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: ingress-nginx-scaledobject
namespace: ingress-nginx
spec:
maxReplicaCount: 10
minReplicaCount: 1
pollingInterval: 10
cooldownPeriod: 2
advanced:
horizontalPodAutoscalerConfig:
behavior:
scaleDown:
stabilizationWindowSeconds: 10
scaleTargetRef:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
name: hello-web
triggers:
- type: prometheus
metadata:
serverAddress: http://kube-prometheus-stack-1640-prometheus.prometheus:9090/
metricName: nginx_http_requests_total
query: sum(rate(nginx_http_requests_total{job="ingress-nginx-exporter"}[12s]))
threshold: '100'
另外本文使用了一个 golang 压测工具 https://github.com/link1st/go-stress-testing,需要压测的时候可以了解一下。
蚂蚁金服 Kapacity
Kapacity 是蚂蚁金服开源的扩缩容解决方案,该方案的好处在于提前预测流量趋势,提前扩容,而不是到达阈值之后再进行扩容(从被动扩容变成了主动扩容),但是感觉该方案有点复杂,有空研究一下。