目录
概述
从 K8s 1.25 开始 cgroupv2 特性变成 stable 状态,很多生产环境也都开始在使用 cgroupv2 了。本文初步研究下 cgroupv2 中的一些概念模型,并通过一些例子来学习下 cgroupv2 的一些特性。
cpu 限制
与 cgroupv1 类似,cgroupv2 支持绑定 cpu(或者进一步绑定 numa)、配额、分片,几种限制 cpu 使用的方式,我们首先通过配额来验证下流程。
1) 新建 cgroup,在 /sys/fs/cgroup 目录新建目录 lr90
cd /sys/fs/cgroup
mkdir lr90
2) 配置 cpu quota,在 cgroupv2 中,cpu.max 文件用于配置进程可使用的 quota,包含两个值:$MAX $PERIOD,表示在 $PERIOD 周期内,进程可使用的配额为 $MAX。假设我们进程最多使用 0.5 个 cpu,则可以配置 $MAX 为 $PERIOD 的 1/2。我们将 50000 100000 写入到 cpu.max 文件中。
3) 启动一个消耗 cpu 的进程,写一个无限循环的 shell,因为是单进程所以最多会消耗 0.5 个 cpu,期望利用率是 50%。
#!/bin/bash
while true; do :; done
假设文件名字为 shell.sh,通过命令 ./shell.sh & 执行该 shell,并置于后台运行,执行之后,会打印进程 id。
lr90@u:~/cgroupv2$ ./shell.sh &
[1] 26281
4) 将进程加入到 lr90 这个 cgroup。在将进程加入到 cgroup 之前,我们先看一下系统的负载。
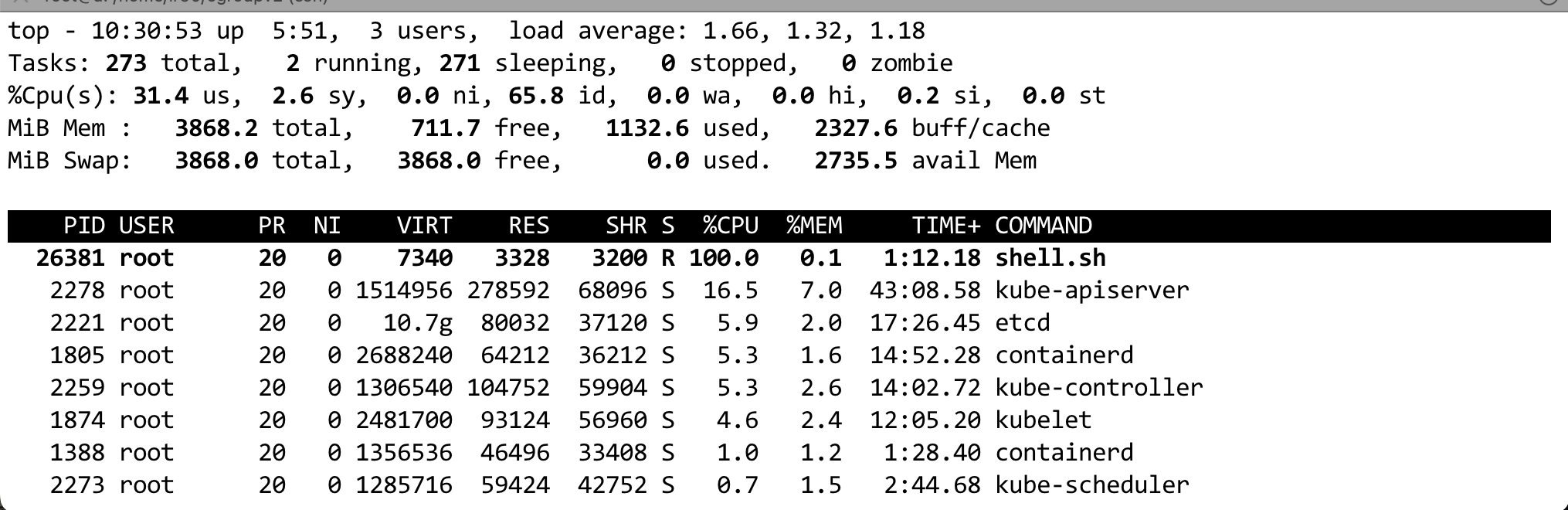
通过命令 echo 26281 > /sys/fs/cgroup/lr90/cgroup.procs 将进程加入到 cgroup。期望 cpu 利用率是 50%。
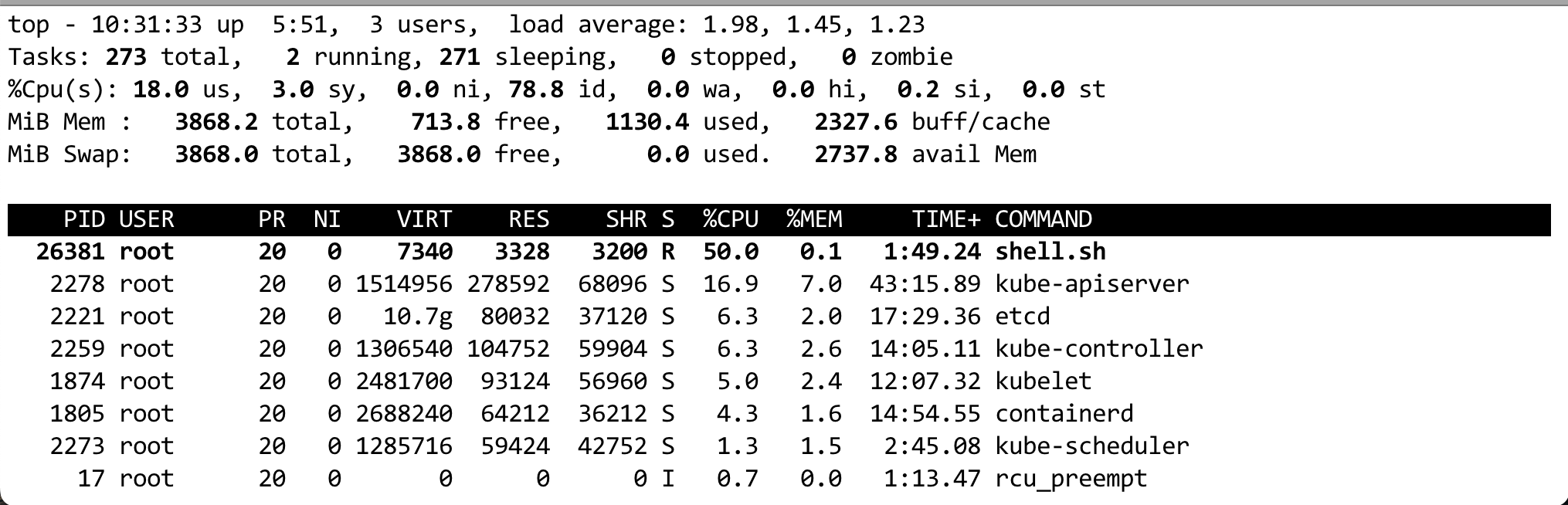
5) 查看 cpu.stat,我们先看一下这个文件中字段的含义:
- usage_usec: 控制组中的进程使用的总 CPU 时间(微秒数)。它包括用户态和内核态的 CPU 使用时间
- user_usec: 控制组中的进程在用户态使用的 CPU 时间(微秒数)。
- system_usec: 控制组中的进程在内核态使用的 CPU 时间(微秒数)。
- nr_periods: 控制组中的进程已经经过的 CPU 使用周期的数量。在 cgroup v2 中,CPU 使用是通过周期(periods)来控制的,每个周期内的 CPU 使用量由 cpu.max 控制。
- nr_throttled: 控制组中的进程被 CPU 限制(throttled)的次数。
- throttled_usec: 控制组中的进程被 CPU 限制的总时间(微秒数)。
在理解 cpu.stat 中字段的含义之后,我们看下其内容。从下面内容中可以看出,880 个周期中,有 878 个周期被限流了,并且被限流的时间和运行时间基本一致,因为我们设置的 $MAX 是 $PERIOD 的 1/2。
root@u:/sys/fs/cgroup/lr90# cat cpu.stat
usage_usec 43947739
user_usec 43564536
system_usec 383202
core_sched.force_idle_usec 0
nr_periods 880
nr_throttled 878
throttled_usec 42480939
nr_bursts 0
burst_usec 0
6) 查看 cpu.pressure,关于 cgroupv2 资源 pressure 的文档可以参考 PSI - Pressure Stall Information,该指标用来衡量资源的紧张程度,取值范围为 [0,1000],值越大则资源越紧张。应用程序可以自动监听这个文件,并在资源压力较大时主要调整 cpu.max 值,但是如何定义 资源压力较大 是个问题,目前看上去需要通过 grafana 实时监控这个值,并且需要观察业务实际的运行情况?
root@u:/sys/fs/cgroup/lr90# cat cpu.pressure
some avg10=34.82 avg60=34.97 avg300=32.09 total=411247665
full avg10=34.82 avg60=34.97 avg300=32.09 total=411247665
memory 限制
在 memory 控制器中,有几个配置文件比较重要,在测试之前先简单介绍一下这些文件
- memory.current: 当前内存使用量,包括当前 cgroup 以及子 cgroup,包括 page cache、网络 buf 等。
- memory.max: 是一个 hard limit,超过时会 oom。
- memory.high: 是一个 soft limit,当超过 high 的时候,进程可能并不会被立即 kill,这个配置可以当做一个预警(通过 Prometheus 和 grafana 配置)。当进程超过 high 的时候,系统会尝试回收内存,比如清理缓存。
- memory.low: 尽可能保证的内存,低于 memory.low 时,进程的内存不会被回收,除非内存不足。
- memory.min: 一定要保证的内存,在系统内存紧张(memory.min 主要在内存紧张时起作用),并且进程申请到的内存低于 memory.min 时,系统会尝试回收内存,并触发 oom,并且内存使用低于 memory.min 的进程,oom score 比较低,不容易被 kill。
下面通过例子来查看 memory 控制的工作过程。
1) 配置 memory.max 10M
echo "10M" > /sys/fs/cgroup/lr90/memory.max
2) 配置 memory.high 8M
echo "8M" > /sys/fs/cgroup/lr90/memory.high
3) 写一个脚本,不停消耗内存,这里是用 go 写的,下面程序每秒申请 2M 内存,最多申请 200M。预期会 OOM。
package main
import "time"
func main() {
mb := 1024 * 1024
memSize := 2 * mb
count := 100
buf := make([][]byte, count)
for i := 0; i < count; i++ {
a := make([]byte, memSize)
for j := range a {
a[j] = byte(j % 256) // 随便给个值
}
buf[i] = a
time.Sleep(1 * time.Second)
}
println("Completed all allocations")
}
4) 将进程写入到 cgroup
echo 28558 > /sys/fs/cgroup/lr90/cgroup.procs
不过我发现一个问题,尽管我程序申请的内存超过了 10M,但是并没有 oom 发生,并且内存使用始终在 memory.high 附近。发生了啥?排查之后发现是 swap 的问题,需要在 cgroup 中禁用 swap,命令为 echo 0 > memory.swap.max,如果不起作用,可能还需要通过命令 swapoff -a 在系统层面禁用。
low 0
high 14191
max 43
oom 1
oom_kill 2
oom_group_kill 1
io 限制
相比于 cgroupv1,cgroupv2 支持 buffio 限制,实现了真正意义上的 io 隔离,这一块后面有时间再补充。
TODO