目录
1. 概述
总体来说,阿里云使用 gpu 比较方便,总体能做到开箱可用,运维复杂度相对较小。
并且支持丰富的调度策略,在开发测试阶段,通过共享 gpu 能有效降低成本。
在费用层面,除去 gpu 机器的费用,其他费用感觉都是可以接受的,比如调度 ai 套件是免费的,监控收取数据存储费用。
但有些功能具有特定的机型限制,比如 eRDMA 只支持 ebmgn7ex 等特定机型,另外在落地具体业务时,还要结合具体的业务特点来对整个运维链路进行梳理,以降低成本并最大化提高效率。
2. 使用及使用约束
2.1 安装 ai 套件
ack ai 套件主要用来协助 gpu 的调度,集群中要使用 gpu 资源,首先要安装 ai 套件,主要是 《ack-ai-installer》,这个在 ack 的应用市场一键安装就可以了,具体可参考下面的 应用测试 章节。
安装 ai 套件会安装阿里云的 cgpu 组件,从目前阿里云的文档《什么是GPU容器共享技术cGPU》来看,cgpu 是一种容器运行时,同时也是支持 gpu 共享的关键技术,感觉跟 NVIDIA 的 nvidia-container-toolkit 定位是一样的。
ai 套件是免费使用的,但是依赖的其他资源可能会收费,比如云盘。ai 套件主要包括一组 daemonset,基本组件如下,其中负责共享与隔离的 daemonset 的在节点部署上是互斥的(基于 ack.node.gpu.schedule 标签,此标签的含义参考本文 gpu 调度部分)。
lr90@sj % kubectl get daemonset -n kube-system --kubeconfig ./kubeconfig
cgpu-core-installer 0 0 0 0 0 ack.node.gpu.schedule=core_mem 7h41m
cgpu-installer 0 0 0 0 0 ack.node.gpu.schedule=cgpu 7h41m
gpushare-core-device-plugin-ds 0 0 0 0 0 <none> 7h41m
gpushare-device-plugin-ds 0 0 0 0 0 <none> 7h41m
gpushare-mps-device-plugin-ds 0 0 0 0 0 <none> 7h41m
gputopo-device-plugin-ds 0 0 0 0 0 ack.node.gpu.schedule=topology 7h41m
migparted-device-plugin 0 0 0 0 0 <none> 7h41m
nvidia-device-plugin-recover 0 0 0 0 0 ack.node.gpu.schedule=default 7h41m
2.2 创建节点池
当需要使用 gpu 机器的时候,只需要创建一个 gpu 节点池就可以了,创建节点池的过程跟普通 gpu 节点池一致,但是要选择 gpu 实例,阿里云支持 gpu 的机型列表为 《ACK 支持的 GPU 实例规格族》。
当创建完节点池后,节点池中的节点会有可分配的 GPU 资源 aliyun.com/gpu-count 以及 aliyun.com/gpu-mem。
allocatable:
aliyun.com/gpu-count: "1"
aliyun.com/gpu-mem: "15"
aliyun/member-eni: "13"
cpu: 3920m
ephemeral-storage: "37693705359"
hugepages-1Gi: "0"
hugepages-2Mi: "0"
memory: 14368792Ki
nvidia.com/gpu: "0"
pods: "13"
2.3 业务 pod 声明 gpu 资源
业务如果需要使用 gpu,需要在资源的 limits 中声明 gpu 资源。
resources:
limits:
aliyun.com/gpu-mem: 3 # 设置 gpu 显存大小。
3. gpu 调度
阿里云中 gpu 的调度由 Kubernetes scheduler 和阿里云 ai 套件共同完成,基本上是开箱即用,不需要Kubernetes 运维管理员和应用开发者做额外的工作。
3.1 显存与算力调度
阿里云 gpu 调度策略是通过给节点打上特定的 label 来声明的,因此一般在创建节点池的时候打上对应label,同时同一个节点池的节点使用同一种调度策略。阿里云有下面 label 及 value:
- 标签
ack.node.gpu.schedule,对应下面几个 value:- default(或者不含有
ack.node.gpu.schedulelabel): 独占 gpu 调度,以单个 gpu 卡为最小单位分配 gpu 给 pod。 - cgpu: 显存隔离算力共享, 在这种调度模式下, pod 可通过资源
aliyun.com/gpu-mem申请一张卡的显存资源,但是 gpu 的算力是共享的。 - core_mem: 显存和算力都隔离,pod 可通过资源
aliyun.com/gpu-memaliyun.com/gpu-count申请显存和算力资源,其中算力资源是一个百分比,表示使用一个单卡百分之多少的算力。 - share: 显存隔离算力共享,但是不需要安装 cgpu 服务,cgpu 是阿里云基于内核虚拟 gpu 隔离的容器共享技术。即多个容器共享一张 gpu 卡,从而实现业务的安全隔离,提高 gpu 硬件资源的利用率并降低使用成本。具体参考 《通过Docker命令行使用cGPU服务》。
- topology: gpu 拓扑感知调度,节点仍以单个 gpu 卡为最小划分单元,为 pod 分配 gpu 资源。每个 pod 分配到的 gpu 卡的数量考虑了 gpu 卡之间的通信带宽。比如如果申请了两个 gpu 卡,则调度时,会考虑将两个相邻的 gpu 卡一起分配给 pod,这样这两个卡通信带宽比较高。
- mig: 动态开启 mig 功能,开启 mig 功能后,节点上报的不再是 gpu 卡的数量,而是 mig 实例数,pod 也以 mig 实例数来申请资源。这个需要硬件支持,需要 NVIDIA A100 及更新的卡才支持这个功能。
- default(或者不含有
- 标签
ack.node.gpu.placement,对应下面几个 value:- spread: 该 value 仅在节点开启共享 gpu 调度的时候才有效,当节点上存在多张 gpu 卡时,该策略能够允许申请 gpu 资源的 pod 打散在各 gpu 上
- binpack(没有
ack.node.gpu.placement的默认行为是 binpack): 该 value 仅在节点开启共享 gpu 调度的时候才有效,该策略能够允许申请 gpu 资源的 pod 先占满一张 gpu 卡,再占用另一张 gpu 卡,避免资源出现碎片。
这部分内容主要参考阿里云文档《GPU节点调度属性标签说明及标签值的切换方法》。
注意 如果往 Kubernetes 集群中加入一台机器,而没有做任何配置,比如没有添加 ack.node.gpu.schedule label,那么 ack 集群默认执行的是独占 gpu 调度,参考《使用Kubernetes默认GPU调度》,应用可以通过 nvidia.com/gpu:1 来申请资源,但是无法实现多个 pod 共享 gpu。
阿里云的 cgpu 组件只在显存和算力需要隔离的时候才会部署,也就是标签 ack.node.gpu.schedule 的值为 cgpu 或者 core_mem 的时候才需要部署,这点从 ai 套件部署的 daemonset 中也能看出来。
3.2 NUMA 拓扑调度
NUMA 拓扑调度参考文档《启用NUMA拓扑感知调度》,区别于 gpu 拓扑调度,NUMA 拓扑调度关注 cpu 于 gpu 之间的通信,及 pod 分配 cpu 和 gpu 资源时,尽量不跨 NUMA,减少跨 NUMA 通信带来的代价。
启用 NUMA 调度需要阿里云另一个组件 ack-koorinator 协同支持,仅支持 gpu 计算型超级计算集群实例规格族 sccgn7ex 及灵骏节点。
K8s 原生拓扑调度:
K8s 基于节点中的 Topology Manager 原生支持拓扑感知调度,该控制器收集各个 hint provider 提供的调度建议综合一个最佳的调度策略,然后分配资源给 pod。如果节点资源不能满足 pod 资源需求,则 admit pod 失败,比如会有 TopologyAffinityError,AdmissionError 报错。
目前 K8s 内置的 hint provider 有 cpu-manager、memory-manager
等,对于 cpu-manager 我们比较熟知的是其在 static 策略下,对 guaranteed pod 提供的绑核功能。而 memory-manager 则可以将 pod 的内存申请放置在同一个 numa 上。以 memory-manager 为例,其工作过程如下:

原生 topology manager 只是专注单个节点的资源分配,在调度器层面只知道 cpu、gpu 是否已经分配,无法感知到拓扑(gpu 编号等),阿里云环境基于 ack-koordinator 组件中的 ack-koordlet 支持拓扑上报到调度器,在调度 pod 时,需要在 annotation 中添加配置:
apiVersion: v1
kind: Pod
metadata:
annotations:
cpuset-scheduler: required # 启用绑定CPU
scheduling.alibabacloud.com/numa-topology-spec: | # 表明此Pod的NUMA拓扑需求
{
"numaTopologyPolicy": "SingleNUMANode",
"singleNUMANodeExclusive": "Preferred",
}
跟 topology manager 类似,阿里云支持的调度策略有:
- SingleNUMANode:pod 调度时 cpu 与设备需要放置在相同 numa 下,如果没有满足条件的节点,pod 将无法被调度。
- Restricted:pod 调度时 cpu 与设备需要放置在相同的 numa 集合下,如果没有满足条件的节点,pod 将无法被调度。
- BestEffort:pod 调度时尽量将 cpu 与设备放置在相同 numa 下,如果没有节点满足这一条件,则选择最优节点进行放置。
4. 监控
4.1 阿里云监控方案
阿里云的对于 gpu 的监控基于 NVIDIA 的 DCGM(Data Center GPU Manager) 来做的。DCGM 是 NVIDIA 提供的一种用于监控、管理和优化数据中心中 NVIDIA GPU 设备的工具和框架。DCGM 的主要目标是简化数据中心中大规模 GPU 集群的管理,提供有关 GPU 的详细信息、健康状况、性能统计以及故障诊断等关键数据。
开启 gpu 监控需要开启阿里云的 ARMS(Application Real-Time Monitoring Service) 服务,阿里云的 ARMS 服务涵盖了 Prometheus/Grafana,目前看跟我们的 ob 监控服务有重合。参考《什么是应用实时监控服务ARMS?》。
4.2 基于 nvidia-smi 的社区方案
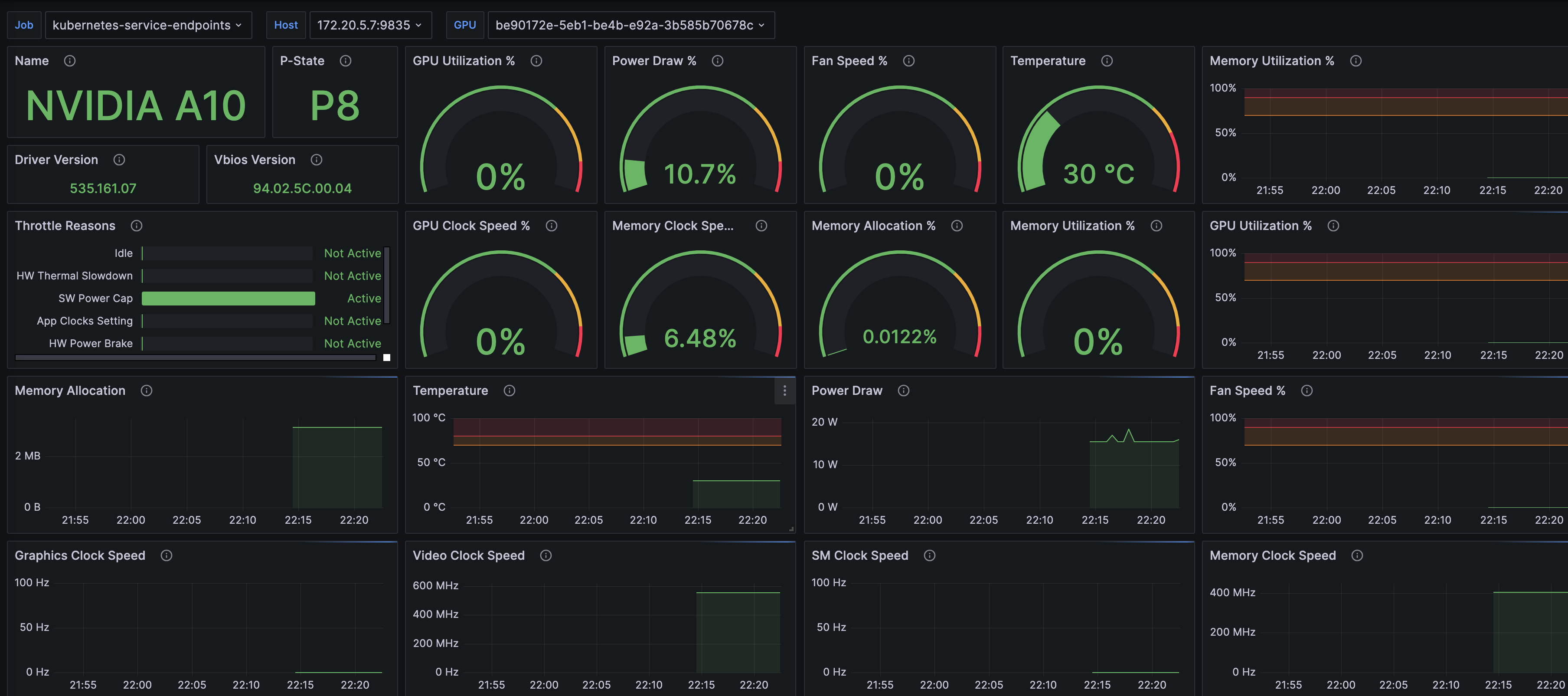
如果集群节点没有部署 DCGM,可以基于社区的 nvidia_gpu_exporter 来监控 gpu,该项目比较简单,只依靠 nvidia-smi 命令实现监控,并提供了 grafana dashbroad,总体来说部署和使用都比较简单。
通过 helm 进行安装:
helm repo add utkuozdemir https://utkuozdemir.org/helm-charts
helm install my-release utkuozdemir/nvidia-gpu-exporter
不过一般情况下不能使用默认的 values 进行安装,默认 values 文件是针对 Ubuntu 环境的,在 centos 环境下,需要修改动态库的挂载路径,下面是已经修改好的,Ubuntu 环境下直接用原来的 chart 就可以。
volumes:
- name: nvidiactl
hostPath:
path: /dev/nvidiactl
- name: nvidia0
hostPath:
path: /dev/nvidia0
- name: nvidia-smi
hostPath:
path: /usr/bin/nvidia-smi
- name: libnvidia-ml-so # 注意:改这两个挂载项
hostPath:
path: /usr/lib64/libnvidia-ml.so
- name: libnvidia-ml-so-1
hostPath:
path: /usr/lib64/libnvidia-ml.so.1
# -- The container mount configurations for the volumes
# @default -- see [values.yaml](values.yaml)
volumeMounts:
- name: nvidiactl
mountPath: /dev/nvidiactl
- name: nvidia0
mountPath: /dev/nvidia0
- name: nvidia-smi
mountPath: /usr/bin/nvidia-smi
- name: libnvidia-ml-so
mountPath: /usr/lib/x86_64-linux-gnu/libnvidia-ml.so
- name: libnvidia-ml-so-1
mountPath: /usr/lib/x86_64-linux-gnu/libnvidia-ml.so.1
这个监控展示如下面所示,感觉能满足大部分需求
另外也可以部署 DCGM exporter 来实现 gpu 监控,不过其往往作为 gpu operator 的一部分进行安装。
5. RDMA
RDMA(Remote Direct Memory Access)是一种允许计算机之间直接访问远程计算机内存的技术,而无需通过传统的操作系统栈或网络协议栈,从而可以显著提高数据传输速度和降低延迟。
5.1 条件约束
-
使用支持 eRMDA 的实例规格,目前仅支持 gpu 实例规格:ebmgn7ex、ebmgn7ix、ebmgn8is,参考《在GPU实例上配置eRDMA》。这些实例是裸金属实例,使用前应该需要初始化:包括选择系统镜像以及初始化 rdma 设备。
-
创建挂载支持弹性 RDMA 的网卡 ERI。
弹性 RDMA 网卡(Elastic RDMA interface,简称 ERI),是一种可以绑定到 ECS 实例的虚拟网卡,ERI 需要依赖一个弹性网卡 ENI 开启 RDMA 功能。
-
使用 GPU 节点时,NVIDIA 驱动版本需要高于 470.xx.xx 以上。
5.2 使用
目前看到对 gpu 实例的 ERI 配置是在 ecs 层面配置的,而不是在节点池层面,需要做两个工作:1)在镜像配置中勾选 安装 eRDMA 软件栈;2)在弹性网卡配置中勾选弹性 RDMA 接口。
应用层使用 RDMA 接口可以通过 Verbs 协议,Verbs 是 RDMA 的应用层协议,通过 Verbs 提供的接口,应用可以直接与 RMDA 硬件通信,实现远程直接内存访问。
eRDMA 是免费的,依赖的 ENI 是收费的。
6. 应用测试
6.1 前置条件
在 ack 集群配置中,部署 ai 套件,支持 gpu 调度。
6.2 创建 gpu 节点池
使用 gpu 机型 ecs.gn6i-c4g1.xlarge 创建节点池,同时因为要测试显存隔离算力共享调度模式,在创建节点池的时候,需要配置 label: ack.node.gpu.schedule=cgpu。
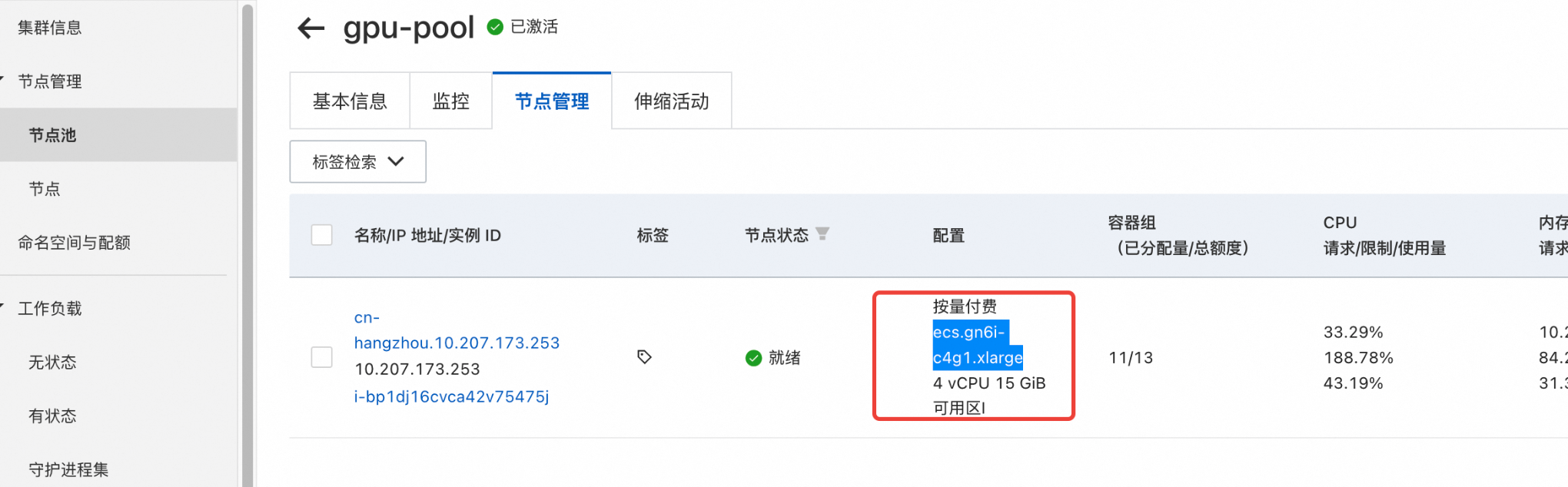
查看节点可分配资源:
allocatable:
aliyun.com/gpu-count: "1"
aliyun.com/gpu-mem: "15"
aliyun/member-eni: "13"
cpu: 3920m
ephemeral-storage: "37693705359"
hugepages-1Gi: "0"
hugepages-2Mi: "0"
memory: 14368792Ki
nvidia.com/gpu: "0"
pods: "13"
6.3 运行测试用例
按照阿里云文档《运行共享GPU调度示例》部署 tensorflow 测试用例,
apiVersion: batch/v1
kind: Job
metadata:
name: gpu-share-sample
spec:
parallelism: 1
template:
metadata:
labels:
app: gpu-share-sample
spec:
containers:
- name: gpu-share-sample
image: registry.cn-hangzhou.aliyuncs.com/ai-samples/gpushare-sample:tensorflow-1.5
command:
- python
- tensorflow-sample-code/tfjob/docker/mnist/main.py
- --max_steps=100000
- --data_dir=tensorflow-sample-code/data
resources:
limits:
# 单位为GiB,该Pod总共申请了3 GiB显存。
aliyun.com/gpu-mem: 3 # 设置GPU显存大小。
workingDir: /root
restartPolicy: Never
6.4 使用 kubectl 查看集群 gpu 资源使用情况
inspect cgpu 是阿里云提供的 kubectl 插件,用于查看集群内 gpu 的资源分配情况,mac 下的安装方式为:
wget http://aliacs-k8s-cn-beijing.oss-cn-beijing.aliyuncs.com/gpushare/kubectl-inspect-cgpu-darwin -O /usr/local/bin/kubectl-inspect-cgpu
使用方式如下:
lr90@sj lr90 % KUBECONFIG=./kubeconfig kubectl inspect cgpu
NAME IPADDRESS GPU0(Allocated/Total) GPU Memory(GiB)
cn-hangzhou.10.207.173.253 10.207.173.253 3/15 3/15
------------------------------------------------------------------------
Allocated/Total GPU Memory In Cluster:
3/15 (20%)
从上面输出可以看出:1)集群中有一个 gpu 节点;2)该节点有一个 gpu 卡;3)这个 gpu 卡一共有 15G 显存,已经分配了 3G。
6.5 在容器内查看 gpu 信息
nvidia-smi是一个命令行工具,用于监控和管理 NVIDIA GPU设备的状态。它通常用于 NVIDIA 驱动程序安装之后,帮助用户检查 GPU 的健康状况、性能、温度、功耗等信息,以及管理和控制 GPU 设备。
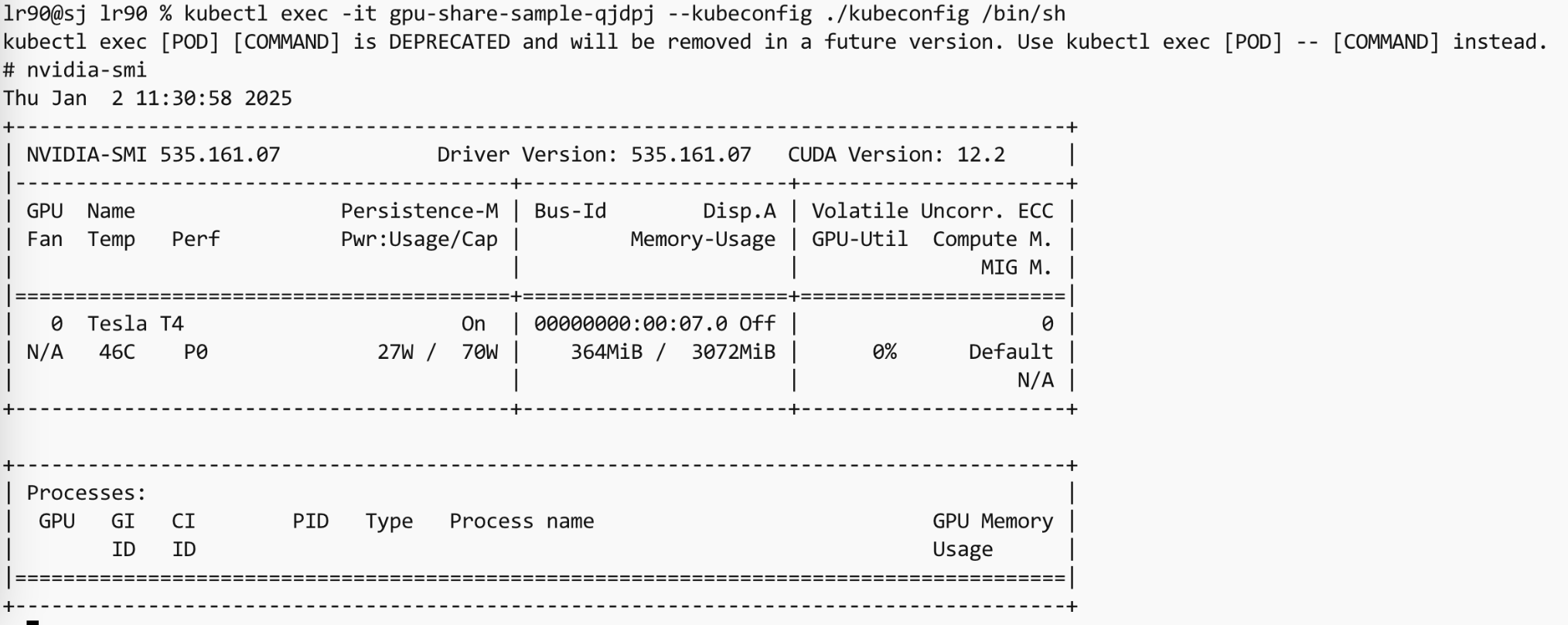
从上面输出可以看出,该容器内只有 3072MiB 显存。这一点从容器的日志中也能看出来。

7. 开源社区方案
7.1 Kubernetes DevicePlugin
Kubernetes 社区原生支持 gpu的方式是 device-plugin,device-plugin 以 daemonset 的方式运行在集群中的每个节点上,向 kubelet 汇报(通过/var/lib/kubelet/device-plugins目录下的 unix sockets 进行通信)当前节点的自定义资源数量,比如 nvidia.com/gpu: 2,表示节点有两个 gpu 卡。pod 应用可以像申请 cpu/memory 一样申请 gpu 资源。
DevicePlugin 的主要缺点在于运维复杂,DevicePlugin 不会安装 NVIDIA 驱动以及 nvidia-container-toolkit(这个是 NVIDIA 容器运行时,让应用在容器内能使用 gpu),也没有监控方案。NVIDIA 官方的 plugin 地址为 k8s-device-plugin。
7.2 NVIDIA operator
NVIDIA operator 是 NVIDIA 官方提供的在 Kubernetes 集群中使用 GPU 的解决方案。相比于 K8s 原生的 Device plugin 解决方案,NVIDIA 能自动安装 NVIDIA 驱动、Controller Toolkit、Device-Plugin、监控等组件。功能比较完善。
NVIDIA operator 支持两种方式共享 GPU,分别是 Time-Slicing GPUs in Kubernetes,GPU Operator with MIG。
7.3 HAMi
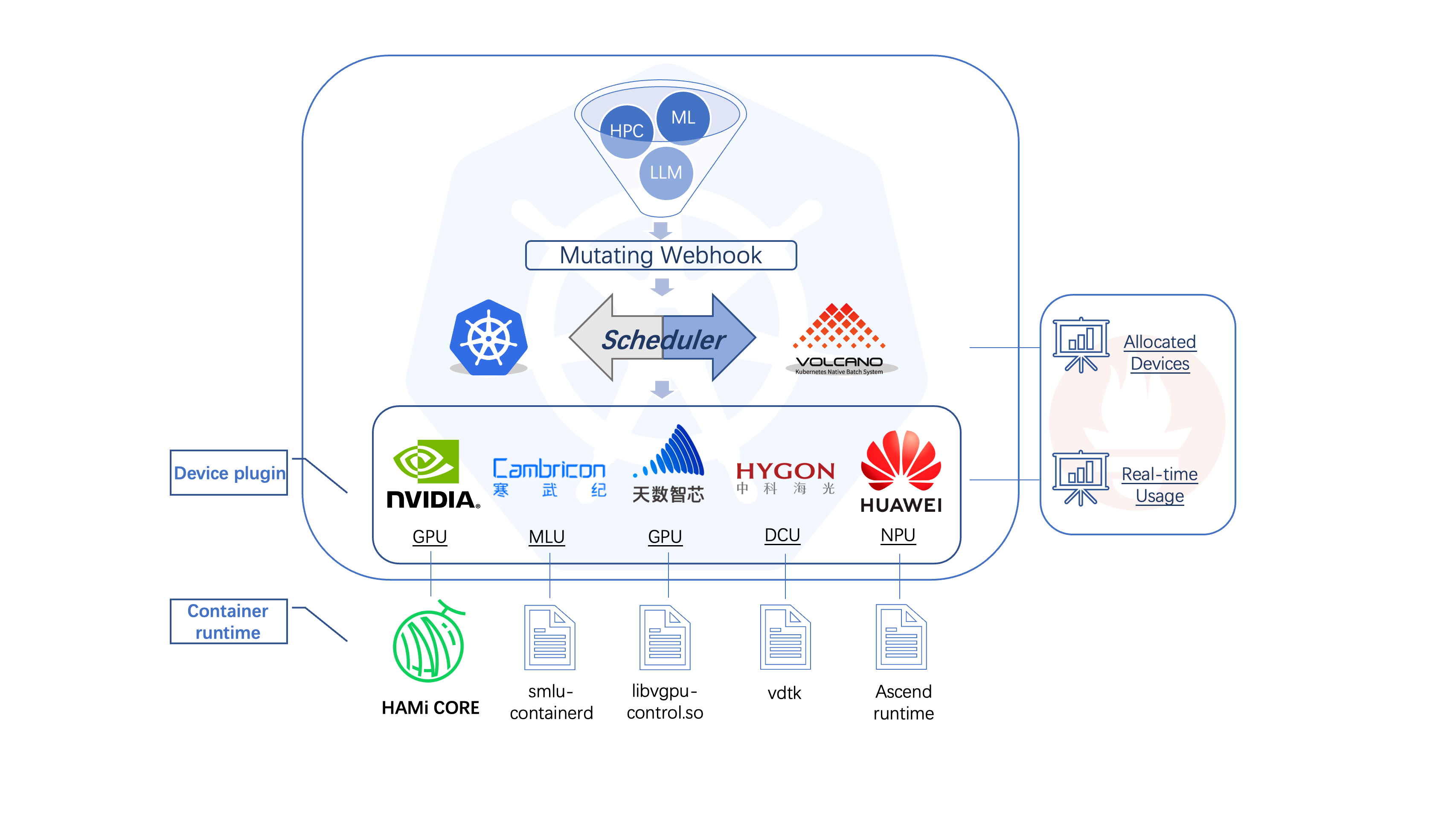
HAMi Kubernetes 社区中异构设备管理开源项目。它可以管理不同类型的异构设备(如 NVIDIA GPU、华为 NPU、寒武纪 MLU、DCU 等),实现异构设备在 Pod 之间的共享。HAMi 旨在消除不同异构设备之间的差异,为用户提供统一的管理接口,无需对应用程序进行任何修改。
同时支持通过调度策略在不同 pod 之间共享 gpu,支持的的共享策略有:1)通过设置核心使用率(百分比),进行设备的部分分配;2)通过设置显存(单位:MB),进行设备的部分分配;3)预计在 2.5 版本之后对 NVIDIA A100 (以及更新的 gpu卡)进行动态 MIG(Multi-Instance GPU) 分片。