目录
karpenter 概述
karpenter 是一个公有云环境下 K8s 集群扩缩容的项目,主要功能为:在有 pod pending 的时候触发集群节点扩容,以及在节点资源利用率比较低的时候执行缩容,意在节省成本。
根据官方文档 https://karpenter.sh/docs/,其工作过程为:
- Watching:监听集群中被标记为 unschedulable 的 pod。
- Evaluating:根据 pod 的调度约束(资源、拓扑等)来选择可调度的节点池 NodePool,并创建 NodeClaim,(NodeClaim 是 karpenter 与第三方供应商的通信 api,用来声明对 Node 的资源需求)。
- Provisioning:这个主要是第三方 CloudProvider 来做,根据 NodeClaim 通过第三方 sdk 创建出具体的 Node(比如 aws ec2 或者阿里云 ecs),并添加到 K8s 集群中。目前关注的第三方代码有 karpenter-provider-aws、karpenter-provider-alibabacloud。
- Disrupting:销毁资源利用率比较低的节点或者 empty 的节点,如果有必要会弹出新的节点来替换旧节点。
概念
karpenter 使用过程中涉及到几个概念(crd): NodeClass、NodePool、NodeClaim。其中 NodePool 和 NodeClaim 是 karpenter 核心项目 提供的 api,是跟供应商无关的。NodeClass 则涉及到供应商底层 infra 的一些信息,是由供应商 provider 提供的,比如阿里云的 provider karpenter-provider-alibabacloud。
NodeClass 以及 NodePool 是由集群管理员事先在集群中创建好的,应用开发者只需要在 pod 应用中声明调度约束,不需要知道 NodeClass 以及 NodePool 的存在,但要知道后者的拓扑结构。
NodeClass
NodeClass 描述的是底层 infra 的一些信息,是跟供应商绑定的。以阿里云 karpenter-provider-alibabacloud 为例,NodeClass 的定义如下:
// ECSNodeClassSpec is the top level specification for the AlibabaCloud Karpenter Provider.
// This will contain the configuration necessary to launch instances in AlibabaCloud.
type ECSNodeClassSpec struct {
VSwitchSelectorTerms []VSwitchSelectorTerm `json:"vSwitchSelectorTerms" hash:"ignore"`
VSwitchSelectionPolicy string `json:"vSwitchSelectionPolicy,omitempty"`
SecurityGroupSelectorTerms []SecurityGroupSelectorTerm `json:"securityGroupSelectorTerms" hash:"ignore"`
ImageSelectorTerms []ImageSelectorTerm `json:"imageSelectorTerms" hash:"ignore"`
KubeletConfiguration *KubeletConfiguration `json:"kubeletConfiguration,omitempty"`
SystemDisk *SystemDisk `json:"systemDisk,omitempty"`
Tags map[string]string `json:"tags,omitempty"`
ResourceGroupID string `json:"resourceGroupId,omitempty"`
}
从上面定义中,我们看到 NodeClass 关注的信息有:
- 虚拟机交换机 vswitch,在公有云环境下,交换机跟可用区一一对应的,选择不同的交换机意味着选择不同的可用区。
- 选择安全组,配置防火墙策略。
- 选择 ecs 使用的镜像,通过这个配置,我们可以自定义节点使用的镜像。
- 系统磁盘类型(对应 storageclass,如 cloud/cloud_ssd 等),容量大小,性能级别(pl1/pl2/pl3/pl4)。
- ecs 所具有的 tag,ecs tag 是 infra 层面的元信息,区别 K8s Node 的元信息。
- Kubelet 参数定制化配置。
- 资源组配置,资源组配置在给资源分类,并进行成本分析的时候尤其有用。
可以看到上面 ECSNodeClass 的定义基本接近在控制台创建一个阿里云节点池的配置。
NodePool
NodePool 是由 karpenter 核心项目维护的,其定义跟供应商无关的,主要定义调度拓扑相关信息。NodePool 具体配置如下:
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
template:
metadata:
labels:
billing-team: my-team
annotations:
example.com/owner: "my-team"
spec:
nodeClassRef:
group: karpenter.k8s.aws # Updated since only a single version will be served
kind: EC2NodeClass
name: default
taints:
- key: example.com/special-taint
effect: NoSchedule
startupTaints:
- key: example.com/another-taint
effect: NoSchedule
expireAfter: 720h | Never
terminationGracePeriod: 48h
requirements:
- key: "karpenter.k8s.aws/instance-family"
operator: In
values: ["m5","m5d","c5","c5d","c4","r4"]
minValues: 5
- key: "karpenter.k8s.aws/instance-cpu"
operator: In
values: ["4", "8", "16", "32"]
- key: "topology.kubernetes.io/zone"
operator: In
values: ["us-west-2a", "us-west-2b"]
- key: "kubernetes.io/arch"
operator: In
values: ["arm64", "amd64"]
- key: "karpenter.sh/capacity-type"
operator: In
values: ["spot", "on-demand"]
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized | WhenEmpty
consolidateAfter: 1m | Never # Added to allow additional control over consolidation aggressiveness
budgets:
- nodes: 10%
- schedule: "0 9 * * mon-fri"
duration: 8h
nodes: "0"
limits:
cpu: "1000"
memory: 1000Gi
weight: 10
NodePool 定义了以下信息:
- K8s 节点需要的 label、annotation、taint、startupTaints,这些是 K8s 层面的元信息。
- 定义了一组 nodeSelector,用来选择创建实例用的 instanceType。这些 nodeSelector 涵盖了机型、规格、地域、付费类型等信息。供应商 CloudProvider 在构建 InstanceType 列表时,会根据实际实例信息给 InstanceType 打上这些 label。
- 定义了 consolidate 信息,目前支持两种 consolidate 策略:WhenEmptyOrUnderutilized/WhenEmpty,但是 Karpenter 并没有通过阈值来定义什么时候是
Underutilized,这个后面再研究一下。
集群中至少有一个 NodePool 实例 Karpenter 才能正常工作,并且推荐节点池都是互斥的,即 pod 按照调度约束只能调度到其中一个节点池。如果有多个节点池可以调度 pod,Karpenter 会按照权重 weight 调度节点池。
NodePool requirements 定义的 label 是供应商为 Node 添加的 label,以阿里云为例,阿里云在通过 sdk api 拿到机型信息的时候,会根据机型的信息,给机型添加对应的 label,如核数、cpu 架构等。
NodeClaim
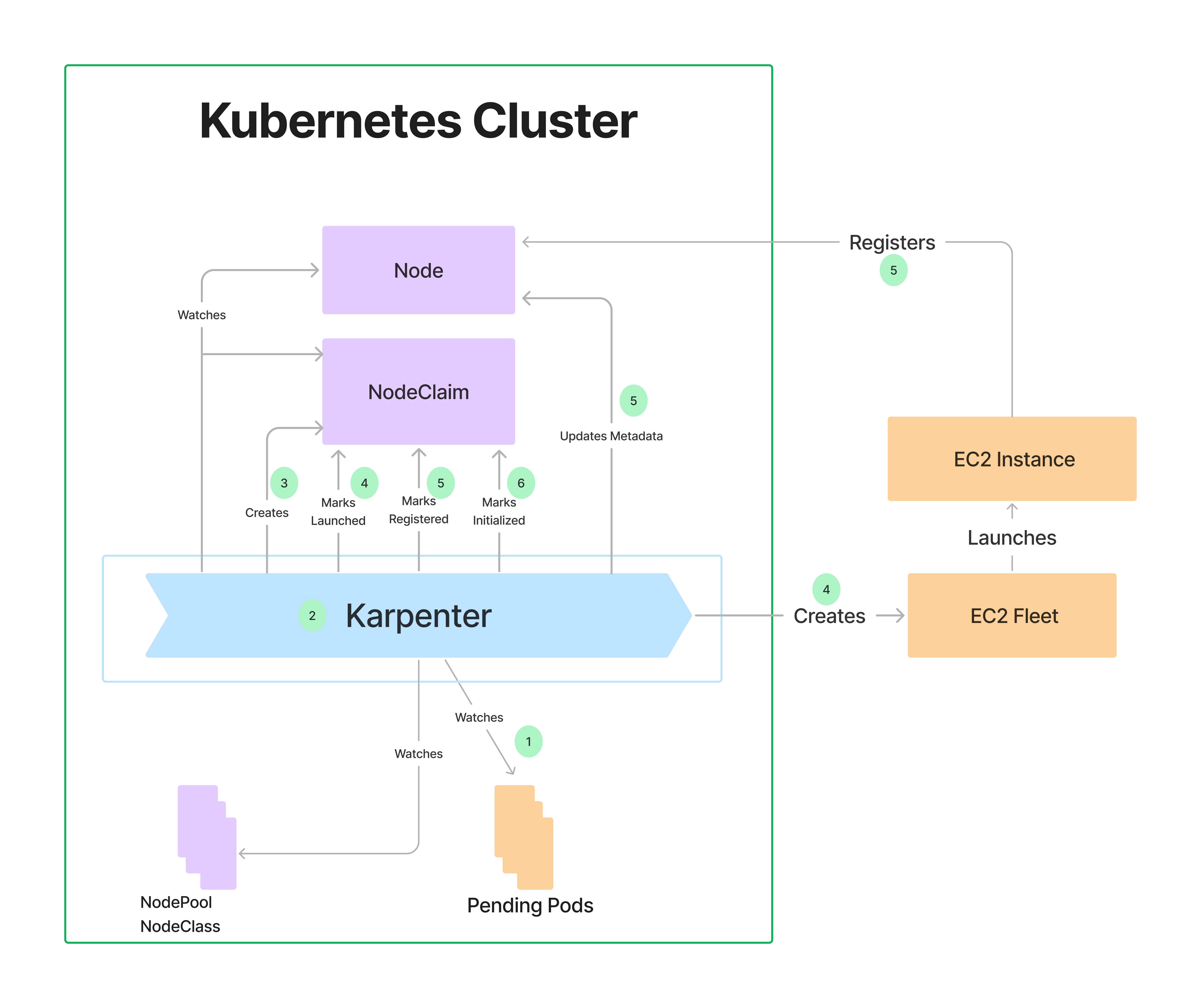
当集群中存在 pending 的 pod 的时候,Karpenter 会寻找匹配的 NodePool 以及 NodeClass,并创建满足 NodePool 以及 NodeClass 约束的 NodeClaim。并调用供应商的代码来 create 这个 NodeClaim,create 这个 NodeClaim 一般包括下面步骤:1)选择匹配的机型;2)创建虚拟机实例;3)注册到 K8s 集群中;4)初始化。
官方文档 中给出的架构如下,其实创建虚拟机的大部分工作是在第三方代码,即 CloudProvider 代码中实现的。
调度
Karpenter 中的调度的概念跟 K8s 中的调度概念一致,不过在不同阶段进行了抽象。根据职责分工,Karpenter 将调度或调度约束分为三个层次:
第一层是供应商基础设施,如虚拟机机型、cpu 架构、购买方式等,这个是供应商决定的;
第二层是集群管理员定义的 NodePool,NodePool 定义了集群中所具有的节点池,并通过 label 的形式声明了这些节点池所具有的调度特性;
第三层是应用自身,根据已有节点池定义业务的调度属性,比如可用区,affinities 属性等。
consolidate
按照官方文档karpenter disruption: automated methods, karpenter 有四种自动删除节点的情况:
- Expiration: 指在 NodePool cr 中指定了
spec.disruption.expireAfter这种情况比较好处理。 - Consolidation: 理解为
整合,是指自动删除闲置的 node 或者替换为更便宜的 node,以提高资源利用率和降低成本,这个是我们主要关注的内容。 - Drift: 这个不太知道怎么翻译,是指 NodePool spec 变化的情况,比如节点池原来用
c5.xlarge机型,修改之后改用c6.xlarge机型,此时需要将原来的 c5.xlarge 机型删除。 - Interruption: 中断,是指节点异常退出的情况,比如 spot 实例被回收,Node 出现故障等。
上面四种情况都是通过 disruption 控制器来做的,karpenter disruption 控制器的工作流程如下:
- 寻找一组可能被 disruption 的节点,称为 candidate。如果节点上运行的 pod 含有 annotation
karpenter.sh/do-not-disrupt: "true"则不移除节点。 - 对于每个 candidate,如果上面还有 pod,则进行模拟调度,如果当前集群中的节点不能满足 pod,可能会触发弹出新的节点(replacement)。
- 对每个 candidate 添加污点
karpenter.sh/disrupted:NoSchedule防止pod 调度过去。 - 对于需要进行节点置换的 pod,等待新的节点 ready,如果新节点弹出失败,则从第一步 1)重新开始。
- 删除 node,并等待优雅退出成功。其中驱逐 pod 是通过 K8s 的 Eviciton API 进行的。
- 退出之后,重新从 1)开始。
对于 consolidate 而言,又分为三种情况:1)闲置节点 consolidate;2)多节点替换为其他另一个节点(启发式的);3)单节点替换为其他另一个节点。 consolidate 的配置可以参考 Karpenter: an introduction to the Disruption Budgets,示例如下:
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized
consolidateAfter: 600s
budgets:
- nodes: "0" # block all
reasons:
- "Underutilized" # if reason == underutilized
schedule: "0 15 * * mon-fri" # starting at 15:00 UTC during weekdays
duration: 9h # during 9 hours
- nodes: "1" # allow by 1 WorkerNode at a time
reasons:
- "Empty"
- "Drifted"
上面配置的含义为:1)在周一到周五的工作日,从 15:00 开始的九小时内,禁止缩容 underutilized 类型的 node,也就是禁止节点置换或者 pod 迁移。2)但节点为空(Empty)或者供应商 NodeClass 或者 NodePool 配置有变化的时候(Drifted)每次只允许缩容一个节点。
安装部署
以阿里云为例看一下安装部署流程,参考官方文档 Set up a cluster and add Karpenter。
文档中有好几个步骤,分别为准备阿里云 ack 集群、部署 Karpenter helm chart,部署 NodeClass以及 NodePool,以及部署测试应用。